What Breaks When Your Test Suite Grows From 20 to 500 Tests
Learn what breaks when a Playwright suite scales from 20 to 500 tests, and how to fix it with test data isolation, flakiness math, smarter retries, and faster CI pipelines.

Your CI pipeline used to be a point of pride. Green checkmark in three minutes, every time. Now it's a 45-minute chore that your developers have learned to ignore. The dashboard is full of red, and everyone assumes it's environment noise rather than a real regression. You've gone from high-trust feedback loop to "retry and pray."
When you cross the 300 test mark, you discover that your initial framework wasn't built for scale. It was built for speed at low volumes. The debt from those first 250 tests can't be repaid through incremental fixes or better selector hygiene.
A growing test suite exposes three realities that basic tutorials ignore. First, infrastructure becomes a constraint. Naive parallel strategies lead to 90-minute CI pipelines that block development. Second, flakiness compounds. A 1% failure rate per test becomes a near-certain pipeline failure across 500 tests. Third, observability gaps widen. When you can't run the full suite locally, you lose the ability to tell environment noise from real regressions.
This article breaks down what fails at each stage of growth and how to fix it.
Decision Framework: When to Invest
Investment in infrastructure should match the pain your suite causes. This correlates with test count but isn't determined by it. A suite of 50 complex, stateful E2E tests can need more infrastructure than 300 fast, isolated API tests.
These test-count tiers are rough heuristics, not rules:
- 20-50 tests: Standard setup is sufficient. Focus on writing clear, maintainable tests.
- 50-150 tests: Add basic parallelization (
workers: 4in CI). Watch for tests that pass alone but fail in parallel. That's your first sign of isolation problems. - 150-300 tests: Flakiness becomes statistically significant. Implement flaky test tracking, quarantine, and begin evaluating per-worker database isolation.
- 300-500+ tests: Cross-run observability and sharding become valuable. Most teams at this scale need structured solutions.
But the real decision framework is the signals your suite sends you:
| Trigger | Priority Investment |
|---|---|
| CI noise > 20% of runs | Flakiness detection and quarantine |
| Suite runtime > 30 minutes | Sharding and orchestration |
| Local runs > 15 minutes | Tag-based filtering or TIA |
| Frequent race conditions | Per-worker database isolation |
Let the signals guide you, not an arbitrary test count. The sections below cover each of these problems in detail.
Why Shared State Breaks at Scale
The most common pattern in growing test suites is shared data: a common test database with seeded data, Page Object Models for selectors, and two or three retries to paper over intermittent failures. This works fine for 20 tests. It becomes a liability at 200.
Shared state breaks parallelization and undermines test independence even within a single worker. With Playwright's default settings (fullyParallel: false), tests in the same file run serially on the same worker. But if they share a database, the first test can leave behind data that causes the second to fail. That's sequential contamination, and it happens even without parallelism.
When you enable full parallelization (fullyParallel: true) or split tests across many files, multiple workers may collide over the same database, creating true race conditions. One worker creates a "user" while another requests a list of users and sees unexpected data. If the first worker deletes that user before the second finishes its assertions, the test fails. No amount of waiting or retries can fix a failure rooted in shared state.
Manual cleanup scripts make this worse. Cascading failures are common: one test creates a user, another creates an order for that user. When cleanup tries to delete the user while the order still exists, foreign key constraints block the deletion. Stale data accumulates, and future tests fail unpredictably. The time spent building more elaborate cleanup logic is wasted, because that logic breaks just as easily.
Three test data isolation strategies
There are three ways to eliminate shared state, each with different tradeoffs:
1. Isolated databases per worker (recommended)
Each Playwright worker gets its own database schema or container instance. You dynamically construct schema names using workerInfo.parallelIndex in a worker-scoped fixture. Setup happens once per worker, and cleanup is simply dropping the schema. No complex scripts, no leftover data. In our experience, lightweight Postgres schemas provision in 2-5 seconds depending on schema complexity. Containerized databases take longer (30-60 seconds cold, 5-10 seconds with pre-warmed images), but offer stronger environment isolation. This removes shared-state interference from the database layer, but external dependencies, async workflows, and global config can still introduce flakiness. The approach requires infrastructure that supports dynamic schema creation.
2. API-driven data setup
Instead of manipulating the database directly, you use Playwright's request fixture to call your application's own APIs for data creation and cleanup. This is highly portable (it works anywhere the app is running) and tests through more of the stack. The tradeoff is speed: API calls are slower than direct database operations, and you're adding a dependency on the API itself.
3. Transactions per test (limited use)
Wrapping each test in a database transaction that rolls back at the end sounds appealing, but it rarely works for E2E tests. Your application server maintains its own database connection pool, separate from the test's connection. The server can't see the test's uncommitted data, and the test can't roll back the server's changes. This is fundamentally constrained by architecture, not just external services. Only consider it for tests that query the database directly (unit or integration tests).
For most teams, isolated databases per worker provides the best balance of speed and determinism. The provisioning overhead is negligible compared to the hours lost debugging non-deterministic failures. At 500 tests, strong isolation is non-negotiable.
To debug where shared state is causing friction in CI, start by identifying tests that pass alone but fail when running in parallel.
Here's how shared vs. isolated approaches compare in practice:
| Factor | Shared Database | Isolated Databases |
|---|---|---|
| Speed | 10–15 min (Parallel but unstable) | 10–15 min (Parallel and reliable) |
| State Management | Seeded and cleaned | Fresh for every worker |
| Failure Rate | 15–30% of runs (across teams we've worked with) | < 2% of runs |
| Debugging Time | High (Unclear root causes) | Low (Failures are real) |
| Infrastructure Cost | Low | Medium |
Solving the data isolation problem is the first step toward stability, but even the best architecture is vulnerable to the math of distributed failures.
The Flakiness Trap
There are many ideas about how to address flakiness, from better timeouts to more retries. But the math of high-volume testing makes these approaches unsustainable.
Given a per-test flake rate of p and n tests, what is the probability of a fully green run?
The formula: P(success) = (1 - p)^n
- p: The probability of a single test failing (flake rate)
- n: The total number of tests in the suite
Example: 1.5% flake rate across 300 tests
P(success) = (1 - 0.015)^300
P(success) ≈ 0.0107 (or ~1%)
With a flake rate of only 1.5%, a 300-test suite succeeds about 1% of the time. At 50 tests, the same rate gives you roughly 47% success. At 500 tests, it drops below 0.1%. Even a 1% per-test flake rate across 500 tests means less than a 1% chance of a clean pipeline.
This formula assumes failures are independent. In reality, failures often correlate: one broken dependency or environment problem can cause dozens of tests to fail together. The math still illustrates why even low per-test flake rates become catastrophic at scale. In practice, suite reliability may be slightly better when failures cluster (easier to debug a single root cause) or worse when one failure cascades into many.
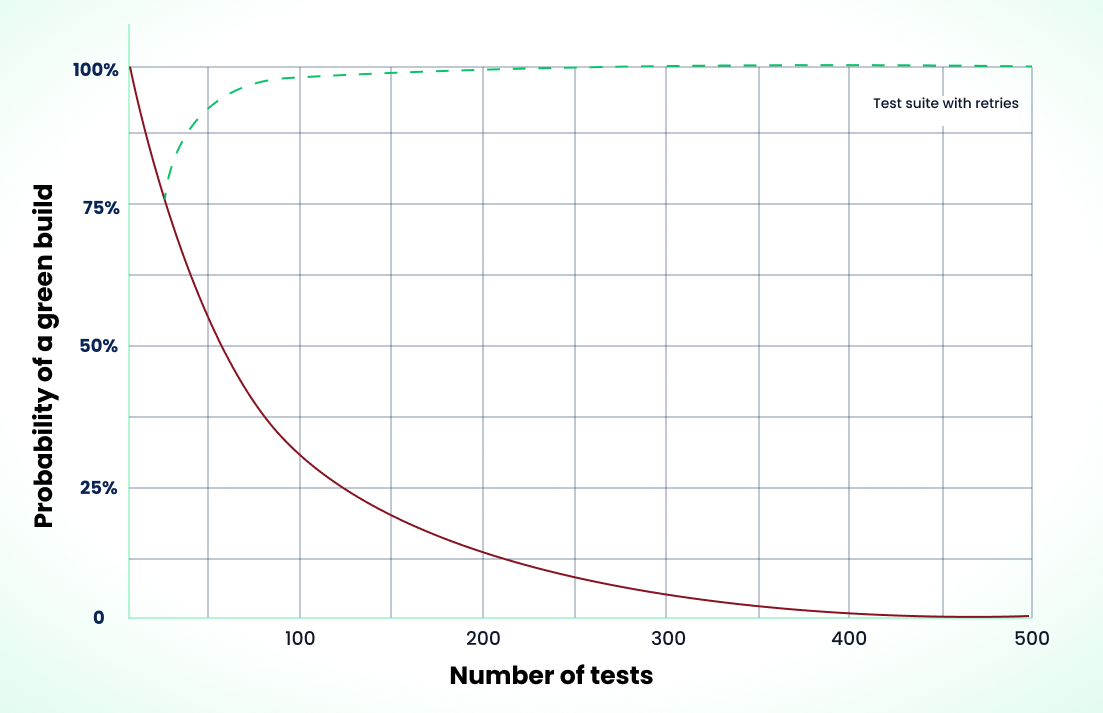
If you don't know your per-test flake rate, here's how to measure it: enable retries: 1 in your config for a sprint. Playwright categorizes tests that fail on the first attempt but pass on retry as "flaky." Count those across your runs and divide by total test executions. That gives you a baseline to plug into the formula above.
For a detailed breakdown of these mathematical relationships, see this QA Tech Lead's reality check on scaling test automation.
Masking retries vs. diagnostic retries
Most teams respond to flakiness by setting retries: 2. But not all retries are equal.
Masking retries are what the industry rightly criticizes: adding retries to make red pipelines green without investigating root causes. This conceals race conditions, masks infrastructure instability, and kicks technical debt down the road. Your team learns to ignore failures, and the suite's signal degrades.
Diagnostic retries are a deliberate strategy. A common Playwright pattern is retries: 1 with trace: 'on-first-retry'. Run the test once; if it fails, retry and capture a trace on the second attempt. This gives you forensic data without the overhead of tracing every successful run. The difference is intent: if you're adding retries and ignoring failures, you're accumulating debt. If you're using retries to gather better debug information while actively fixing underlying flakiness, you're using them as a tool.
Even diagnostic retries should be a temporary bridge, not a permanent crutch. What separates senior teams from the rest is quarantine discipline. They use flaky test tracking to identify intermittently failing tests, move them to a quarantine suite that can't block the main pipeline, and require a stress test (20-100 consecutive passes) before the test can return. The principle matters more than the number: quarantine forces resolution before reintroduction. For a complete quarantine and fix playbook, see What Is a Flaky Test and How to Fix It.
Retries add time. Quarantine adds discipline. The goal is always to eliminate flakiness at its source, using retries only as a diagnostic bridge while you stabilize the suite.
When Local Testing Stops Working
Lost feedback speed is one of the most destructive effects of a growing suite. When you could run 20 tests locally in two minutes, you stayed in a tight red-green-refactor loop. When 300 tests take 45 minutes, local testing gets abandoned. The burden of discovery shifts entirely to CI.
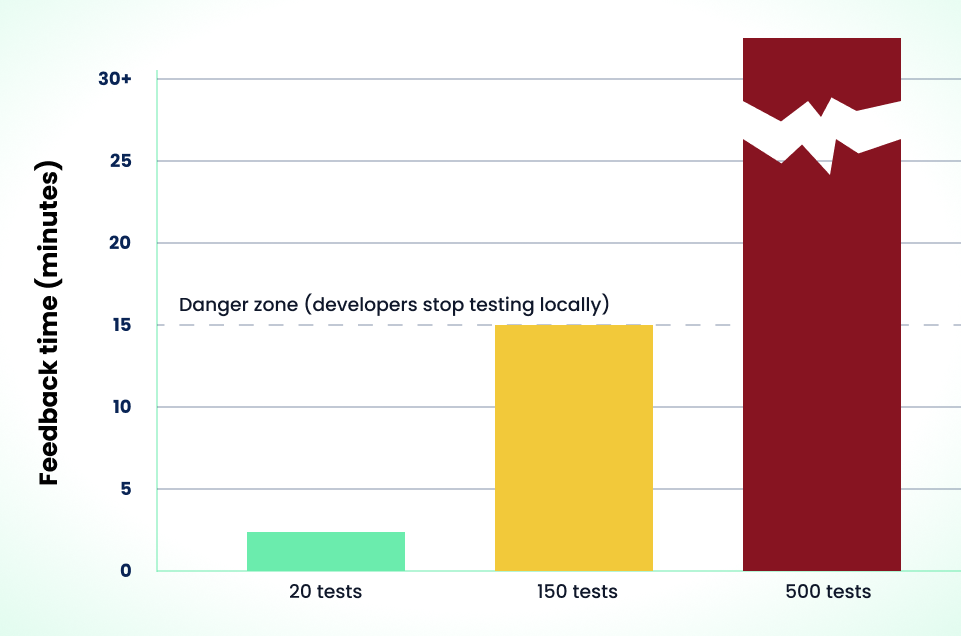
The cost isn't idle time. It's context-switching. You write code, push, and wait 20 minutes only to find a test failure long after you've moved on to something else. For a team of 10 engineers, if each relies on CI instead of local testing five times a week, that's 50 forced context switches weekly. Each one means stopping what you're doing, recalling the original change, and debugging a failure you wrote 20 minutes ago. The cognitive overhead compounds far beyond the raw minutes.
The pragmatic first step is native filtering. Before investing in complex solutions, use what Playwright provides out of the box:
--grepto run tests matching a pattern--projectto target specific browsers or configurations (run only Chromium locally, save cross-browser for CI)- Tag-based filtering (e.g.,
test.describe('checkout', { tag: '@smoke' }, () => {})with--grep @smoke)
These flags let you run a focused subset without any custom infrastructure. A developer editing the checkout flow can run npx playwright test --grep @checkout locally in 90 seconds, then let CI handle the full suite. It's not perfect, but it's immediate and low-risk.
Some teams eventually seek Test-Impact Analysis (TIA), which maps code changes to the specific tests that should run. In theory, this keeps the local feedback loop under five minutes. In practice, TIA for E2E browser tests is difficult. Playwright has no native TIA support. Building a dependency graph for a full-stack web app requires custom tooling (parsing imports, tracking API routes, or manually maintaining test-to-code mappings) and carries a real risk of false negatives. TIA is a worthy goal for mature teams with dedicated tooling budgets, but it's not a turnkey solution. For most teams, native filtering is the pragmatic bridge while you work toward faster overall suite performance.
Rebuild Roadmap: Reclaiming Stability
Most teams hit a wall around 150-200 tests. The architecture stops working, and incremental fixes don't help. Rebuilding a suite while features are shipping is difficult, but necessary.
A four-month migration roadmap typically follows this structure:
-
Month 1: Infrastructure Preparation
- Database isolation: Implement per-worker database isolation using worker-scoped fixtures, not global setup. A worker-scoped fixture runs once per worker and can provision unique database schemas:
import { test as base } from "@playwright/test";
export const test = base.extend<{}, { dbSchema: string }>({
dbSchema: [
async ({}, use, workerInfo) => {
const schemaName = `test_schema_${workerInfo.parallelIndex}`;
await setupSchema(schemaName);
await use(schemaName);
await teardownSchema(schemaName);
},
{ scope: "worker", auto: true },
],
});
-
This pattern gives each worker its own isolated schema without complex global setup logic. Establish a flakiness baseline using Playwright's built-in reporters and configure
trace: 'on-first-retry'to debug existing failures. -
Authentication isolation: Rather than reusing the same auth file across workers, configure per-worker storage states using
TEST_PARALLEL_INDEX(bounded between0andworkers - 1, stays stable across worker restarts):
// playwright.config.ts
export default defineConfig({
use: {
storageState: `./auth/worker-${
process.env.TEST_PARALLEL_INDEX || "0"
}.json`,
},
});
-
Generate these files in a setup project or
globalSetupthat creates one storage state per parallel index. Database isolation prevents data collisions; auth isolation prevents session conflicts. Both matter, and they're solved with different mechanisms. -
Month 2: Core Migration. Migrate the 30% most critical tests (checkout, authentication, payment flows) to the isolated architecture. Use
test.describe.serialwhere test steps genuinely depend on each other, but treat it as a last resort. Playwright's docs explicitly discourage serial mode because it couples tests and makes retries slower (the entire group retries together). EnablefullyParallel: trueeverywhere else. Run migrated tests alongside the legacy suite using--project. Measure success by comparing flakiness rates before and after. -
Month 3: Full Migration. Move all remaining tests. Delete legacy cleanup scripts and rely entirely on schema destruction. Key
playwright.config.tsupdates at this stage:- Set
retries: 1withtrace: 'on-first-retry'for diagnostic purposes only. - Enable
fullyParallel: trueacross the suite, since worker isolation guarantees tests won't interfere. - Set
screenshot: 'only-on-failure'so failures produce actionable artifacts without overhead on passing tests. - Use
test.stepto improve reporting granularity across workers.
What goes wrong at this stage: You'll likely discover that some "isolated" tests still have hidden shared-state dependencies: a shared feature flag, a global API rate limit, a cached config. Quarantine those tests, fix the dependency, then re-enable them. If per-worker schemas hit connection pool limits, configure a bounded pool per worker and keep the
workersconfig aligned with your database capacity. For tests that genuinely need cross-user shared state (e.g., testing that admin changes are visible to regular users), use Playwright's multi-context pattern rather than sharing a database between workers. - Set
-
Month 4: Optimization. Tune database provisioning by moving from container-per-worker to lightweight Postgres schemas (or SQLite in-memory for compatible tests), reducing setup time to 2-5 seconds. Fine-tune Playwright's sharding based on historical test duration data: use the JSON reporter (
--reporter=json) to extract per-file durations, identify the slowest spec files, and split them until shard runtimes are roughly even. Playwright's built-in sharding is static (it doesn't use duration data itself), so you're doing the balancing manually by restructuring files. If manual balancing isn't enough, dynamic orchestration tools can automate this. Implement tag-based filtering (--grep @smoke) so developers can run focused subsets locally.
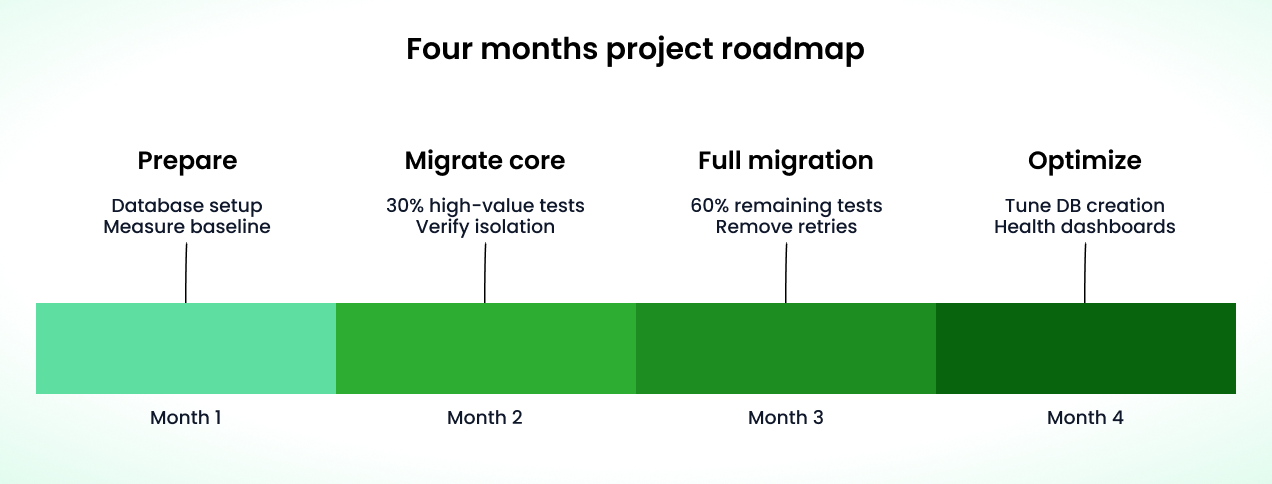
The ROI comes within months. Lower flakiness means higher developer velocity. For most teams, the productivity gains within a year more than repay the initial investment. But this requires more than code changes. It requires a cultural approach to reliable tests where quality is owned by the entire engineering team.
When Playwright Reaches Its Limits
As suites grow beyond 500 tests, orchestration complexity increases. The right solution depends on your scale.
Playwright's --shard=x/y flag splits tests across CI machines. Without fullyParallel, sharding distributes entire spec files across shards (though the same file may land on different shards if you run multiple projects). With fullyParallel: true, it distributes individual tests for better balance. Combined with your CI provider's matrix features (GitHub Actions strategy.matrix, GitLab parallel), teams commonly target sub-10 minute CI times with 10-20 shards.
Static sharding shows strain when test distribution is uneven. If one spec file contains 50 long-running tests while another has 10 fast ones, the heavy shard becomes the bottleneck regardless of how many machines you add. The fix is usually splitting large spec files, not replacing sharding. For a detailed comparison of workers, sharding, and orchestration strategies, see Optimizing Test Runtime: Sharding vs Workers.
For teams at extreme scale (2,000+ tests) or with severe imbalance that splitting files can't solve, dynamic orchestration is worth evaluating. Queue-based systems where workers pull tests as they complete (like Currents or Buildkite's test splitting) distribute work based on historical duration data. These are powerful but add vendor costs and operational complexity. For most teams, they're overkill.
Start with built-in sharding. If you hit bottlenecks, split spec files first. Only invest in orchestration when you have clear evidence the ROI justifies it. And if your suite reaches 500 tests because backend logic is being validated through the browser, the scaling problem is architectural, not infrastructural. Reserve Playwright for critical user paths and push broader coverage to integration or unit tests.
What to Track in a Large Suite
The health of a large suite is measured by the quality of its signal. Here's what to monitor:
- Reliability: First-attempt pass rate, retry rate, and flake rate over time.
- Speed: P95 duration per spec file, total wall time, and the slowest 10 tests.
- Worker utilization: Which workers finish early or late. If one runs for 20 minutes while others finish in five, you have uneven test distribution. Playwright doesn't surface per-worker timing by default. Use the JSON reporter (
--reporter=json) to extract per-file durations, or use a reporting dashboard that tracks worker-level metrics. Split large spec files or adopt duration-aware sharding. - Failure clustering: When several tests always fail together, they likely share a broken dependency. Use Playwright's tagging (
@smoke,@checkout) andtestInfo.annotationsto group failures by feature or service and spot patterns in your reporting. - Ownership: In a 500-test suite, "everyone owns everything" means no one owns anything. Failures become orphaned and accountability evaporates.
Playwright's tagging system solves the ownership problem. Annotate tests with team ownership and route failures to the right people:
test.describe('checkout', { tag: '@team-payments' }, () => {
test('processes credit card', async ({ page }) => { ... });
test('handles PayPal redirect', async ({ page }) => { ... });
});
test.describe('login', { tag: '@team-accounts' }, () => {
test('valid credentials', async ({ page }) => { ... });
});
In CI, extract these tags from Playwright's JSON reporter output and route notifications to team-specific Slack channels, Jira components, or dashboards. When a test fails, the right people know immediately. No triage rotation required.
For a complete metrics framework and dashboard setup, see How to Track the Health of Your Playwright Test Suite.
Defining Success at Scale
At 500+ tests, healthy suites share common characteristics:
- First-attempt pass rate above 98% (flakiness below 2%).
- P95 suite time under 10-15 minutes, depending on deployment cadence.
- Retries used diagnostically, not as a release strategy. Some teams keep a single retry with trace capture while still treating failures as signal worth investigating.
The specific numbers matter less than the trend: flakiness trending down, feedback times holding steady, and engineers trusting the results enough to act on them. When a test fails, your team should understand why, not add a retry and hope.
These metrics also become your communication tool. When leadership asks "are our tests reliable?", point to first-attempt pass rate trending from 85% to 98% over a quarter. When someone proposes skipping tests to ship faster, show them how suite runtime dropped from 40 minutes to 8 after sharding. Data turns test infrastructure from a cost center into a visible productivity investment.
Join hundreds of teams using Currents.
Trademarks and logos mentioned in this text belong to their respective owners.





