How To Build Reliable Playwright Tests: A Cultural Approach
Flaky Playwright tests waste time and trust. Follow best practices and this cultural approach to build stable, team-owned tests that scale with your product.

Teams using Playwright are usually chasing the goal of moving faster and shipping with full confidence. But, as your test suite expands, patterns often emerge. Tests that consistently passed in isolation begin to fail in CI. Builds need to be resubmitted, and engineers start to lose trust in the CI/CD pipeline.
Scaling doesn’t necessarily create new problems on its own, but it does expose what was already fragile. Flaky tests, inconsistent results, and delayed feedback are symptoms of a system never architected to handle growth.
The real challenge is building a foundation that keeps the tests stable as the product, team, and complexity grow. It comes down to three things: structure, culture, and leadership alignment. When these are balanced, your test suite becomes an asset that helps you ship faster and with greater accuracy.
In this guide, you’ll learn how to build Playwright tests that remain dependable as your organization scales, not just through retries or timeouts, but by making stability part of how your team writes and reviews tests.
Reliable Tests Begin with Testing Culture
Most teams write tests, run them in CI, and fix any issues that arise from breaking, but that alone doesn’t make for a sustainable strategy. This means there’s usually a gap between having tests and having a real testing culture that consistently prioritizes quality at scale.
The culture is reflected in the details, such as how quickly a flaky test is fixed, whether test health blocks releases, and whether teams investigate root causes or just re-run until the test passes.
Teams that maintain scalable tests monitor test health as part of their daily routine. Test ownership shouldn’t be ambiguous. Code reviews for tests are as thorough as reviews for features. Flaky tests are fixed within the same sprint they are discovered.
When testing becomes an integral part of how your teams build and ship every day, rather than a final quality check, your test suite grows stronger and scales naturally with your product.
Here's what that looks like in practice.
Sharing Responsibilities, Not Blames
When only the QA own the test ownership, developers may stop treating broken tests as their problem, leading to avoidance of responsibility and triggering the blame game. This can be fixed by redistributing responsibility. How? By giving each team (developers, testers, and DevOps engineers) a clear testing role across the workflow.
The idea behind this distribution is to create a joint responsibility. Developers own the quality of their test coverage. QA focuses on strategy, frameworks, and data design. DevOps maintains the environment that keeps test runs consistent. This way, stability is owned end-to-end.
This can be taken even further by rotating test maintenance duties or assigning test suite owners, per feature, leading to no single person becoming a bottleneck for flaky tests or failing builds. For example, you might rotate who’s in charge of test failures each sprint, or assign test suite owners per feature or domain. When a test breaks, the team that owns the module fixes it, rather than just marking it flaky or skipping it.
With shared ownership, teams move faster because they’re not waiting for one group to clean up another’s failures, shortening the gap between identifying and fixing the issue.
Maintaining Test Health
Shared responsibility works when test health is visible, reviewed, and tied to team goals. That’s how it stays a priority and you ensure stability as the product scales.
A few practices help keep that balance steady:
-
Code reviews. Test changes should go through the same review process as production code. Reviewers should check for proper isolation, clear assertions, and place the tests in the pyramid properly (coming up later in detail). If you never miss a review for production code, don’t miss it for the tests either.
-
Ensure transparency. Maintain a dashboard that displays test runs, failures, and logs. Review it during retros or sprint planning. When everyone can see which tests fail and why, they become a team’s responsibility rather than one person’s burden.
-
A complete product includes test health. Include test flakiness in your definition of “done”. Flag unstable tests on dashboards and make fixing them part of sprint work.
Document Test Patterns
Are you learning from failures in the test suite or repeating them?
Create a shared document that mentions what works, what doesn’t, and why. Show real examples. Flag patterns that cause flakiness. You can even make it specific:
- Every Playwright test runs in a fresh browser context. No shared state at all.
- Test names should follow clear conventions that links them to features or tickets. Anyone, reading a test name, should immediately know what feature it covers.
- Test results are tagged with meaningful cases like, team ownership, feature domain, or quarantine status. This makes them filterable in dashboards like Currents, so you can quickly generate reports, isolate test issues or treat quarantined test separately.
Don’t treat documenting as a one-time effort. Revisit and update the docs regularly, perhaps once a quarter. As your product scales, what used to work for 100 tests may not work for 1,000.
Don’t over-standardize. The goal here is to organize things to reduce uncertainty and provide your team with a shared foundation to build upon. When everyone follows a proper document, new tests become easier to write, old ones are easier to debug, and the entire test suite stays predictable as it grows.
Keep Things Visible
You can’t fix what you can’t see. Use dashboards to track test performance and monitor flakiness rates. Stay proactive before issues escalate.
But visibility will only be useful if you have the context. Try to distinguish between:
- Noise: A test that fails once because of a deployment.
- Signal: A test failing 8 out of 10 times across different environments. This needs attention.
- Trend: A suite that gradually slows down over several months.
With visibility and context, teams stop asking “What caused the build to break?” and start asking “How did the test fail?”, “Are there any patterns here?”, and “Let me check the dashboard.” This is where actual problem-solving begins.
Keeping things visible and in context and noting down the patterns can lead to a constructive cultural shift. But is that all we need? Of course not. These shifts will be more effective if we also have the support of the leadership.
So how do you gain that support, and why does it matter?
How to Get Leadership Support and Why Their Buy-in Matters
Even with great engineers and a proper structure, test reliability won’t scale without leadership support. Scalable reliability matters to leadership just as much as it does to engineers.
When leaders view testing as a cost saver rather than an expense, priorities shift immediately.
Without leadership backing, initiatives like stabilising flaky tests get deprioritized in favour of feature work and are pushed behind during sprints.
With leadership support, this dynamic changes, and test stability becomes a team-level goal. Time for test maintenance is built into sprint planning. Flaky tests block releases in the same way production bugs do, and engineers have the resources to fix systemic issues instead of providing a temporary solution.
Your job is to make the invisible costs of flaky tests, infrastructure issues, etc., visible and to demonstrate to leadership why this matters to business impact.
Here’s how you can do it.
1. Show the Real Cost of Instability
Leadership responds to data. Show them metrics they can act on.
Here’s how to quantify instability:
- Flake rate: How often do tests fail intermittently?
- CI waste: How many hours per week do engineers spend rerunning pipelines, troubleshooting environmental inconsistencies, or waiting on slow feedback?
- Infrastructure fragility: How often do builds fail because of broken dependencies or unstable CI environments?
- Test Coverage Gaps: What production issues could have been prevented with better test coverage?
- Incident history: How many urgent fixes this quarter were caused by bugs that tests should have caught?
Even a 5% flake rate can waste dozens of hours every week. Add CI delays and test retries, and you’re slowing down the process even more. That results in shipping delays and increased costs. Make that visible with real metrics.
2. Connect the Impact to Business Outcomes
Show how unstable tests are negatively impacting business outcomes.
- Speed: “Our end-to-end test runs currently take three hours. Reducing this to one hour means shipping twice as fast.”
- Impact on revenue: “Flaky tests delayed the Friday release by six hours. That cost us around $X in sales.”
- Competitor comparison: “Our competitors release updates more frequently because their pipelines are stable. We can’t because we don’t trust our test suite. The gap keeps growing.”
- Customer retention: “Three outages this quarter could’ve been avoided if the flaky tests had been caught earlier. The customers noticed. ”
Presenting facts like these to management will grab their attention and help inform their decision making.
3. Propose a Phased Plan
Leadership won’t greenlight just promises. They need to see a concrete path with measurable outcomes at each stage.
When you’re making the case for investing in test stability, don’t ask for everything at once. Instead, present a phased plan that proves value at every stage. Each phase should prove clear ROI before requesting resources for the next one.
Here's how to structure your proposal:
Phase 1 - Pilot: Pick one critical test suite. Stabilize it by establishing clear ownership, utilizing analytics, and implementing best practices such as proper isolation. Track the improvement.
- Target:
- Reduce the flake rate in one suite.
- Cut average test runtime.
- Ensure at least 95% of tests pass consistently across CI environments.
- Success metric:
- Zero false failures for two consecutive weeks
Phase 2 - Infrastructure: Once the pilot is stable, invest in better observability. Shared dashboards, execution logs and tools like Currents that help track flaky tests across your entire pipeline.
- Target:
- 100% visibility into test failures within few minutes.
- Reduce CI pipeline re-runs by 50%.
- Success metric:
- Mean time to fix the flaky tests drops by half.
Phase 3 - Scale: Implement these practices across multiple suites. Integrate them into CI workflows and team metrics.
- Target:
- Flakiness stays under 3% across all suites.
- Cutting average feedback time per commit.
- Success metric:
- Release cycle time reduced by 20%.
- Reliability metrics appear on leadership dashboards next to delivery KPIs.
Each phase builds on the previous one and demonstrates ROI before requesting further investment.
4. Tie Stability to Key Metrics
Leaders already track metrics on software performance. Connecting test stability to those will help. Such as:
- DORA Metrics: Deployment frequency, change failure rate and lead time for changes.
- MTTR: Faster recovery when builds fail for legitimate reasons.
- Velocity: Fewer blocked builds mean quicker delivery.
Put these metrics alongside product delivery to position testing as a strategic priority.
5. Position Testing as a Force Multiplier
Stable tests accelerate the whole process. When engineers trust test feedback, they spend less time debugging false failures and instead focus on building features. Every hour saved by not rerunning builds is an hour spent creating value.
Present it clearly to leadership: Investing in test stability boosts team output without expanding headcount. That’s the kind of efficiency they value.
6. Connect Testing to Engineering Goals
Show how testing efficiency is contributing to the impact of team outputs:
- You can deploy confidently.
- Trust feature flags without fearing silent failures.
- Rollbacks are quick with automation.
- New engineers onboard faster when tests reflect reality.
Once leadership understands these values, their support becomes inevitable. And that support only matters if you know how to execute it effectively. That’s where structure comes in next.
Structuring Reliable Playwright Tests in Large Teams: Our Tips
Once direction is clear, teams need the right habits and systems to maintain stability as the product scales. Reliability comes from how you organize ownership, design the test architecture, and connect testing to daily workflows.
Here are a few principles that help large teams maintain dependable Playwright tests at scale.
1. Define Ownership and Process
If no one owns a failing test, it will just linger.
Assign owners for each test area and make their responsibilities visible:
- Decision-making power: Owners can quarantine flaky tests, refine the architecture, or escalate issues within the infrastructure in case they arise.
- Time allotment: Reserve some time of sprint capacity specifically for test maintenance.
- Escalation paths: If a test fails due to infrastructure, owners can reach out to the DevOps or platform teams.
Make ownership visible even in your code using Playwright annotations and tags:
import { test, expect } from "@playwright/test";
test.describe("@checkout @payments-team", () => {
test("should complete a valid payment flow", async ({ page }) => {
test.info().annotations.push({
type: "owner",
description: "payments-team",
});
await page.goto("/checkout");
await page.fill("#card", "4111 1111 1111 1111");
await page.click("button.submit");
await expect(page.locator(".success")).toBeVisible();
});
});
Use team-based tags, such as @checkout or @payments-team, to track scope and ownership. Connect these to dashboards (Currents work really well here) so you can see which teams own which issues and how quickly they can respond to failures.
Make a weekly monitoring routine. Track things like:
- How many tests are without owners?
- How much time do the teams take to respond in case of test failures?
- What’s the fix rate, and what’s the quarantine rate?
When ownership moves from documentation to daily habits, culture naturally shifts, and accountability becomes more achievable.
2. Adopt the Page Object Model (POM)
Before we talk about the testing pyramid, let’s first address how you should structure your test code. The Page Object Model (POM) is a pattern that helps you write clean and scalable tests.
POM separates your test logic from UI elements. Instead of scattering locators and interactions throughout your tests, you create a dedicated class for each page or component. This makes your tests more readable and easier to maintain.
Your UI will change. Update one page object class instead of hunting through dozens of test files. Here's what that looks like:
// pages/CheckoutPage.js
export class CheckoutPage {
constructor(page) {
this.page = page;
this.cardInput = page.locator("#card");
this.submitButton = page.locator("button.submit");
this.successMessage = page.locator(".success");
this.orderIdText = page.locator(".order-id");
}
async fillCardDetails(cardNumber) {
await this.cardInput.fill(cardNumber);
}
async submitPayment() {
await this.submitButton.click();
}
async waitForSuccess() {
await this.successMessage.waitFor();
}
async getOrderId() {
return await this.orderIdText.textContent();
}
}
// tests/checkout.test.js
import { CheckoutPage } from "../pages/CheckoutPage";
test("completes checkout successfully", async ({ page }) => {
const checkout = new CheckoutPage(page);
await page.goto("/checkout");
await checkout.fillCardDetails("4111 1111 1111 1111");
await checkout.submitPayment();
await checkout.waitForSuccess();
const orderId = await checkout.getOrderId();
expect(orderId).toMatch(/ORD-\d+/);
});
You see how the tests read just like plain English? This is the power of POM. Your tests become readable, and if a new team member wants to understand what's happening, they don't have to decode selectors or other complex elements.
3. Use Fixtures to Eliminate Repetition
Now that your page objects are clean, focus on the setup and teardown problem. If you’re copy-pasting the same login steps across multiple tests, you’re doing it the wrong way.
Playwright fixtures enable you to define reusable setup logic that executes before each test. This keeps your tests focused on what they're actually testing:
// fixtures.js
import { test as base } from "@playwright/test";
export const test = base.extend({
authenticatedPage: async ({ page }, use) => {
// Setup: Log in once
await page.goto("/login");
await page.fill("#email", "test@example.com");
await page.fill("#password", "password123");
await page.click('button[type="submit"]');
await page.waitForURL("/dashboard");
// Use the authenticated page in tests
await use(page);
// Teardown happens automatically
},
productInCart: async ({ page }, use) => {
await page.goto("/products");
await page.click('[data-product="123"] .add-to-cart');
await use(page);
},
});
// In your test
test("checkout with authenticated user", async ({
authenticatedPage,
productInCart,
}) => {
// Test starts with user already logged in and product in cart
await authenticatedPage.goto("/checkout");
// ... rest of test
});
This approach eliminates redundancy, making your test suite far more maintainable. Change your login flow once, and every test using that fixture benefits from it.
Whether you use UI-login or API-based login depends on your test objectives; UI login should be tested in a dedicated flow, and API login used for most other tests to reduce noise.
4. Parameterize Tests for Better Coverage
Sometimes you need to run the same test with different data. Instead of copying the entire test multiple times, parameterize it:
test.describe("Dashboard access by role", () => {
const testUsers = [
{ email: "user1@example.com", role: "admin" },
{ email: "user2@example.com", role: "editor" },
{ email: "user3@example.com", role: "viewer" },
];
testUsers.forEach(({ email, role }) => {
test(`${role} can access dashboard`, async ({ page }) => {
await loginAs(page, email);
await page.goto("/dashboard");
await expect(page.locator(".dashboard")).toBeVisible();
});
});
});
This keeps your test suit crisp while expanding the coverage.
5. Structure your Suite Around the Testing Pyramid
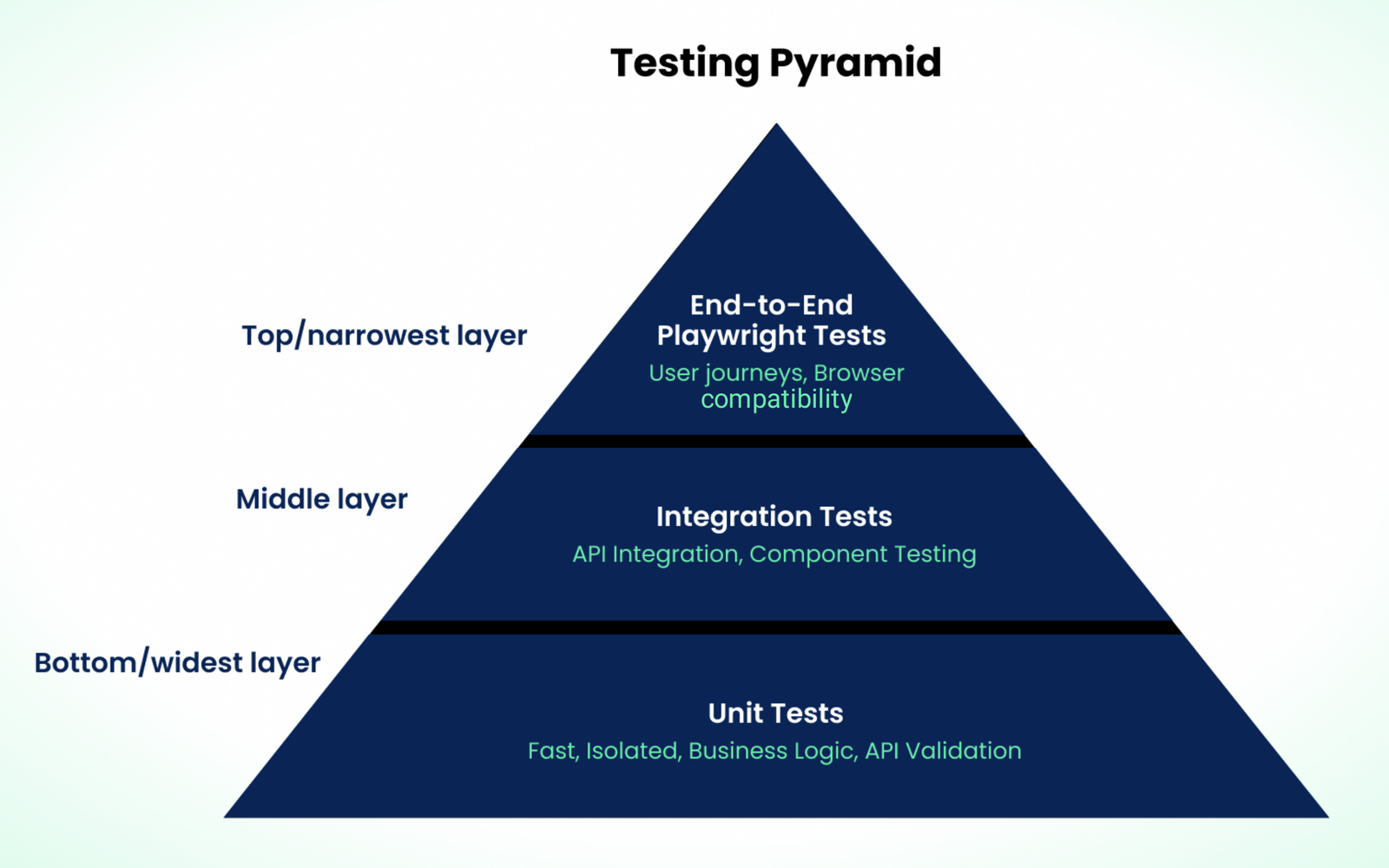
If you’re relying too heavily on the UI tests, it’s only going to make things fragile. A single change in the UI or a network issue can create false failures across test suites. The testing pyramid prevents such chaos by spreading validation across layers.
Unit and Integration Tests (Base Layer)
These handle most of your validation. Business logic, data transformations, and API responses. If this layer is organized, fewer bugs leak to your UI.
What belongs here?
- Business logic: "Do calculations work correctly?"
- Data validation: "Does the API reject invalid emails?"
- Error handling: "What happens when the payment processor is down?"
- Edge cases: "How does the system handle time zones or currency conversions?"
Every bug caught at the unit level is one you don't need to test through the UI:
// Unit test
describe("DiscountCalculator", () => {
test("applies 10% discount for premium users", () => {
const calculator = new DiscountCalculator();
expect(calculator.calculate(100, "premium")).toBe(90);
});
});
// Playwright test
test("checkout shows correct discounted price", async ({ page }) => {
await page.goto("/checkout");
await expect(page.locator(".total")).toHaveText("$90.00");
});
Ensure that the unit tests are fast and focused. They should cover a major chunk of your functional cases. Integration tests verify that services communicate properly. Use reusable utilities for authentication, API mocks, and common setups.
This prevents overloading your Playwright suite with checks that belong at the code level.
Note that the test pyramid is not a silver bullet, and it's a hot topic in the testing community. There are other approaches like the "The Testing Trophy" by Kent C. Dodds or the "Testing Honeycomb" by Spotify. Learn about them and choose the one that works best for your team.
End-to-End Playwright Tests (Top Layer)
Now that you have ensured the foundational layer is stable, use Playwright to verify user flows and product behavior in real browser conditions.
What belongs here?
- User journeys: "Can someone complete a purchase from start to confirmation?"
- Cross-system integration: "Does the payment flow work when it touches five different microservices?"
- Visual verification: "Did this UI change break the mobile layout?"
- Browser compatibility: "Does file upload work in Safari?"
Focus on common user paths, the ones your real users follow most often. Keep each test self-contained with fresh browser contexts, isolated sessions, and clean test data every time. Mock unstable dependencies like analytics scripts or external APIs to reduce environmental noise:
test("checkout flow completes successfully", async ({ page }) => {
// Setup: Authenticate and add item to cart
await loginAsUser(page, "test@example.com");
await addItemToCart(page, "product-123");
// Test: The actual user journey
await page.goto("/checkout");
await page.fill("#card", "4111 1111 1111 1111");
await page.click("button.submit");
// Verify: Only check the critical success indicator
await expect(page.locator(".success")).toBeVisible();
await expect(page.locator(".order-id")).toContainText(/ORD-\d+/);
});
Ensure that the scope is narrow. That’s what separates stable tests from fragile ones.
Supporting Infrastructure
All of the layers above only work if the environment is consistent. How to achieve that?
- Use fixed browser versions and stable network profiles.
- Maintain ephemeral test environments for each branch and PR.
- Integrate CI analytics, such as Currents, to visualize stability across the testing processes.
Consistency across these layers reduces random noise. And it turns debugging into analysis.
6. Use a Centralized Dashboard
In large Playwright environments, scattered test results can kill momentum. When execution logs and failure histories reside across different CI tools, it becomes almost impossible to manage. This is where centralization comes in.
A centralized dashboard brings all your test results, failure trends, and ownership data into one view, making it easier to spot recurring issues and act on them quickly. When you can view data from multiple builds in one place, it becomes clear whether failures originate from unstable environments, shared dependencies, or inconsistent ownership, and this clarity facilitates faster and more accurate fixes.
What to track:
- Flake rate: Ratio of unstable to total runs
- Mean time to fix: Average time to stabilize a failing test
- Failure distribution by ownership: Which teams or modules have recurring issues?
You can also track more advanced analytics:
- Test duration trends: Are tests getting slower over time?
- Pass rate by environment: If staging has a lower pass rate than production, your CI setup might be the issue.
- Peak failure times: If tests fail more often at 9 a.m., it’s likely due to resource contention.
Review these dashboards during retros or while planning a release. This visibility helps teams tackle them early, preventing delivery blocking.
7. Integrate Tools Into the Daily Workflow
Testing feedback needs to be where your teams already work and the tools they use on a daily basis: in pull requests, in Slack threads, in CI pipelines.
Tools like Currents integrate with Jira, GitHub, Slack, and Teams to transform test results into real-time feedback, rather than retrospective reports.
Here’s how:
-
CI Integration: Connect your Playwright test runs directly to the CI/CD pipeline. This allows teams to track flakiness, and execution time after every build. With Currents, CI events can be streamed into dashboards, making it easier to correlate commit history with test outcomes.
-
GitHub Integration: Embed test results in pull requests so reviewers can see if new code introduces instability. With Currents, you can integrate with GitHub to post results as commit status checks or pull request comments, enabling faster, clearer feedback.
-
Slack Integration: Bring critical events straight into team conversations. Send alerts for new flaky tests, repeated test failures, or rising flake rates to ensure timely responses. Tools like Currents can seamlessly integrate Slack, allowing you to post test results of your Playwright tests directly into your Slack channels.
-
Jira Integration: Connect test failures directly to your issue tracking workflow. With Currents’ Jira integration, teams can create new issues, add comments or link test failures to existing Jira issues without leaving the dashboard. Full failure context, like error messages, stack traces, metadata, and test history flows automatically into Jira eliminating context switching and ensuring failures get tracked and prioritized alongside other development work.
8. Control the Environment
Not all flaky tests are poorly written. Sometimes the test itself is fine, it’s the environment where the issues reside. Issues like shared staging data, variable network latency, and mismatched browser versions can create false failures.
Here’s how you can control the environment:
- Fix browser versions and CI specs to prevent environment drift.
- Use isolated, short-lived test environments per PR to avoid shared staging conflicts.
- Apply service virtualization to mock unstable dependencies (third-party APIs, analytics, emails).
9. Track Cultural Maturity Over Time
Testing culture doesn’t improve overnight. To measure progress, look for indicators like:
Ownership maturity:
- Do most tests have a clear owner?
- What's the average response time when a test fails?
- Do teams proactively monitor test health, or only react to CI failures?
Process maturity:
- Are failures debugged immediately or pushed off?
- What percentage of flaky tests get fixed versus quarantined indefinitely?
- Are test failures discussed in sprint planning and retros?
Technical maturity:
- What's your test pyramid distribution? (Is it actually a pyramid?)
- How often do you refactor and improve test patterns?
- Is test code reviewed as rigorously as production code?
Ways to recognize progress:
- Public shout-outs during all-hands meetings for hitting milestones.
- Include test stability in performance reviews.
- Share dashboards and rank teams by flake rate (a bit of friendly competition can be beneficial).
When teams see themselves recognized, it contributes to a healthy competition that drives them to write better tests, thereby strengthening the product.
Final Thoughts
Stable tests aren’t luck. They’re a result of a thorough strategic design and reinforced by consistent daily habits.
Start simple: select one critical suite, give it an owner, and track its performance over time. As these practices spread through shared dashboards, reliable environments, and integrated feedback loops, improvements naturally follow. Test stability stops being a goal and becomes part of how you work.
Think of stable Playwright testing as a signal of maturity. Track the outcomes. You'll see the difference where it matters most: in trust, speed, and the confidence to ship at scale.
Join hundreds of teams using Currents.
Trademarks and logos mentioned in this text belong to their respective owners.


