Optimizing Test Runtime: Playwright Sharding vs. Workers
Long Playwright test runtimes slow CI pipelines. We compare Playwright workers vs. sharding, and when test orchestration becomes the better alternative.

It’s common for CI pipelines to fail during overnight runs. The test suite might take around 45 minutes to finish, holding up other work. By the time new features are pushed, tests from earlier in the week are still running.
Many teams face this problem. When test suites grow past a few hundred tests, runtime can slow down development, especially on CI pipelines where limited resources may extend overnight runs. Developers lose trust in the feedback loop. The idea of fast, reliable automated testing feels harder to achieve.
When tests start slowing you down, running them efficiently becomes important. Playwright provides two ways to speed things up:
- Workers: Run multiple workers on a single machine, dividing your tests across parallel processes that share the same CPU.
- Sharding: Split your suite across several machines in your CI environment for distributed execution.
Both approaches use parallelism, but behave, scale, and fail in different ways. Workers help when your bottleneck is lack of parallelism, not lack of machine capacity. Sharding works better when a single machine can’t handle the load.
In this article, you’ll learn how to choose between sharding and workers in Playwright to best fit your team’s needs. Through practical examples, we’ll show how each approach impacts test runtimes.
How They Differ in Practice
Sharding and workers behave differently because of how they’re executed, and those differences shape your entire testing strategy. Each option has its own setup challenges, cost considerations, and performance patterns that become more noticeable as your test suite scales.
Here are the key points of comparison:
| Factor | Workers | Sharding |
|---|---|---|
| Execution level | Single machine, multiple processes | Multiple machines, each potentially with multiple workers |
| Setup complexity | Simple config change (workers: n) | Requires CI pipeline changes, matrix builds, result aggregation |
| Scalability limit | Bounded by single machine's CPU/memory | Limited only by available CI machines |
| Runtime consistency | Predictable within machine capacity | Can vary due to machine provisioning delays, network issues |
| Cost model | Single machine cost, maximizes resource use | Multiple machines, pay per shard regardless of utilization |
| Failure handling | Runner restarts failed worker, continues | Entire shard fails, no redistribution |
| Maintenance | Configuration file only | CI pipeline scripts, shard count tuning, potential file renaming |
When your test suite grows, running everything on one machine slows things down. Choosing the right scaling approach at different stages of your testing setup helps keep your CI runs reliable.
Playwright Sharding vs. Workers
To choose between sharding and workers, you first need to know what each one does and how they work at different levels of your infrastructure. Here’s how they compare:
Workers: Parallelism Within a Machine
Workers are independent OS processes Playwright spins up on a single machine. When you configure workers: 4 in your Playwright config, you're telling the test runner to create four separate processes.
Each worker gets its own browser instance and runs completely isolated at the process level. However, all workers share the same physical machine and compete for CPU, memory bandwidth, and disk I/O (storage read/write). This resource contention is something to keep in mind when maximizing one machine’s capacity.

By default, Playwright runs test files in parallel across these workers. If you have 20 test files and four workers, the runner distributes those files across the available workers. Worker 1 might run login.spec.ts, Worker 2 handles checkout.spec.ts, and so on.
Playwright assigns work to workers dynamically so that idle workers receive additional files as they finish previous ones, which reduces single-machine idle time compared to static allocation.
Understanding fullyParallel Mode
Before exploring sharding, it’s helpful to understand fullyParallel, a configuration that changes how Playwright distributes tests.
Playwright handles tests differently depending on this setting:
Default behavior (without fullyParallel):
Playwright runs test files in parallel across workers, while tests within a single file run sequentially. For example, if checkout.spec.ts has 10 tests, they execute one after another in the same worker process.
With fullyParallel: true:
Playwright runs individual tests in parallel, even within the same file. All 10 tests in checkout.spec.ts can now execute simultaneously across different worker processes.
With fullyParallel, you cannot rely on beforeAll, stateful fixtures, per-file shared resources, or any sequential test assumptions.
Here’s how you can enable this in your Playwright configuration:
// playwright.config.ts
import { defineConfig } from "@playwright/test";
export default defineConfig({
fullyParallel: true, // Enable test-level parallelism
workers: 4,
});
Sharding: Distribution Across Machines
Sharding splits your test suite across multiple machines. Each machine runs independently in your CI environment. When you execute npx playwright test --shard=1/3, you're telling Playwright to divide the suite into three parts and run only the first part on this machine.

This split happens at the file level, based on alphabetical order. If you have 30 test files and three shards, each shard gets ten files. Shard 1 runs files 1–10, Shard 2 runs 11–20, and Shard 3 runs 21–30. Each shard can also use workers internally, multiplying your parallelism.
Shards run in isolation during execution, since each one is a separate CI job that passes or fails on its own. They don’t share state or track what other shards are doing.
The Load Balancing Problem
Both workers and sharding encounter the same issue: tests don’t always split evenly. If one test file takes ten minutes while others finish in two, that slow one holds up the rest.
Sharding makes this problem even worse. Imagine a test suite with files like these:
auth.spec.ts: 12 minutesdashboard.spec.ts: 10 minutesprofile.spec.ts: 3 minutessettings.spec.ts: 2 minutes
With two shards, alphabetical splitting gives you:
- Shard 1:
auth.spec.ts,dashboard.spec.ts: 20 minutes - Shard 2:
profile.spec.ts,settings.spec.ts: 5 minutes
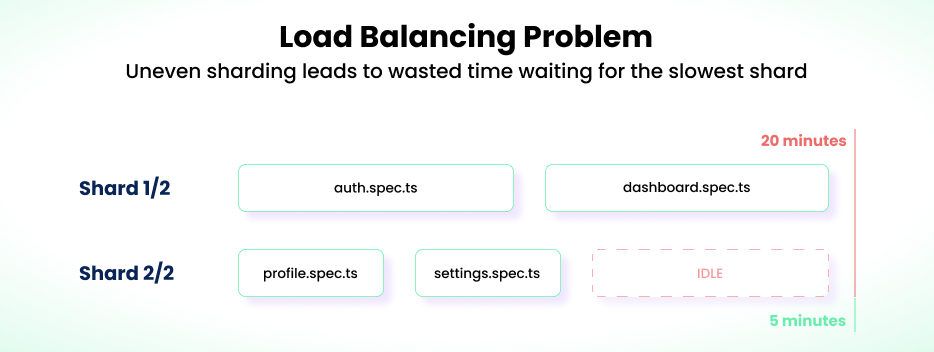
Your total test run takes 20 minutes, but Shard 2 remains idle for 15 minutes, meaning one of the machines isn’t fully utilized.
Workers handle this better since the test runner assigns new files as workers free up. Still, they’re limited by a single machine’s capacity, but within that scope, they remain the most efficient way to parallelize your tests when using a single machine. When used together with sharding, workers rebalance only within a single machine. They cannot redistribute work across shards, so sharding remains statically imbalanced even if workers within each shard are dynamic.
Deep Dive: When to Use Workers for Parallelism
Workers are the default parallelism strategy in Playwright. They're simpler to configure, and they work well for most test suites. Let’s look at when they’re enough on their own before you consider scaling further.
When to Use Workers for Parallel Testing
Workers perform best when your test suite sits in the hundreds, not thousands, with a sweet spot typically between 100 and 800 tests, depending on test duration and machine specs.
A team running 400 tests averaging 15 seconds each has 100 minutes of total execution time, which becomes about 12.5 minutes of wall-clock time on a machine with eight workers, fast enough for continuous integration.
This changes when you scale beyond that, as a suite with 1,500 tests at 20 seconds each produces over an hour of runtime even with eight workers because a single machine can't provide enough parallelism.
The calculus depends on what runtime is acceptable for your team. If workers get you to 18 minutes and your threshold is 20 minutes, you're done, but if you need 10 minutes and workers cap at 15, that's when sharding enters the conversation.
How CPU Limits Affect Worker Performance
The most common mistake teams make with workers is oversubscribing CPU resources.
A GitHub issue from August 2023 highlights this problem, where a developer's tests passed with four workers but failed with 15–20 workers due to timeout errors, even though elements were present in the Document Object Model. The issue wasn't the test logic; it was CPU contention.
When you run more workers than your machine can handle, processes spend more time waiting for CPU cycles than executing as the OS scheduler juggles competing processes, causing Playwright actions to timeout before the browser finishes rendering.
The practical limit depends on your machine. A CI runner with four physical cores works well with 2–4 workers, while an eight-core machine can handle 6–8 workers before losing efficiency. You'll need to test your suite on your own infrastructure to find what works.
Choosing Workers Over Sharding
Workers make sense when you're optimizing for simplicity and your scale fits within single-machine constraints.
Here are scenarios where workers handle the job without needing sharding:
-
A suite with 300–600 tests where individual tests run under 30 seconds each, and total runtime on a single machine with 4–8 workers stays under 20 minutes. The complexity of sharding typically isn't justified.
-
A development workflow where engineers run test subsets locally and can configure 2–4 workers based on their hardware without changing CI infrastructure.
-
Teams that prioritize maintenance simplicity over absolute runtime optimization may prefer workers. They require minimal configuration, while sharding introduces more CI complexity.
-
Tests that are already well-isolated and independent. If your suite was designed for parallelism from the start, workers can handle it efficiently, avoiding state issues or flakiness. You configure the worker count and scale within machine limits, and once that’s maxed out, that’s when sharding enters the picture.
Deep Dive: When to Use Sharding
Sharding isn’t the first thing you use to make tests run faster. You use it when workers alone can’t keep up, since it adds extra setup and coordination. It’s important to know when you’ve reached that point.
When to Scale Beyond One Machine
You run into this limit when your test suite needs more resources than one machine can deliver. Most CI runners only have four to eight CPU cores. If you’re already using eight workers and your tests still take 30 minutes, adding more won’t help. The system will quickly run out of memory, overwork the disk, and strain CPU resources.
For instance, one team with 1,200 tests averaging 25 seconds each achieved a total execution time of 500 minutes. On a single eight-core machine with eight workers, they waited 62 minutes per run, but sharding across four machines with four workers each dropped runtime to 16 minutes by quadrupling their effective parallelism.
The Challenges Sharding Introduces
While sharding speeds things up, it also creates three operational problems that workers handle automatically:
-
Load balancing:
Playwright shards by splitting test files in the order they are discovered (typically alphabetically). If your files have very different execution times, you end up with unbalanced shards, with one shard running for 20 minutes while another finishes in five. The wall-clock runtime is still 20 minutes because the workflow can’t complete until all shards finish. This imbalance reduces the time savings from parallelism, though each machine shuts down after completing its own shard. -
Managing dependencies: When
fullyParallel: trueis enabled, test dependencies can cause issues in both worker and sharding setups. For example, if Test A creates data that Test B expects, Test B may fail when they run separately. Running tests sequentially avoids this, but it only hides the underlying isolation issues that should be fixed.Playwright's project dependencies feature isn’t compatible with external orchestration tools, so you may need to restructure your suite or run dependent projects in separate CI steps.
-
Environment consistency: Each shard runs on a potentially different machine. If provisioning isn't identical, tests fail unpredictably due to different Node versions or cached dependencies. Workers avoid this by sharing the same environment.
When Sharding Makes Sense
Sharding is the right choice once your suite has grown beyond what a single machine can run efficiently, and the complexity pays off in faster results.
Here are a few scenarios where teams typically choose sharding:
- A suite with 500+ tests where single-machine runtime exceeds 30 minutes, and cutting that time in half justifies the extra setup.
- Most tests are truly independent at the file level, with no shared state or implicit ordering, making alphabetical splits less problematic.
- A CI setup that already uses matrix builds for different browsers or configurations, since you're already managing parallel jobs and merging results.
- A team with dedicated DevOps resources should handle sharding setup and performance monitoring, as it requires ongoing tuning to stay efficient.
Teams that don't meet these criteria often find sharding creates more problems than it solves, especially if their suite is under 300 tests or runtime stays below 15 minutes on a single machine.
Sharding works best once workers are fully leveraged, your tests are isolated, and your infrastructure can support it as a scaling strategy, not a default optimization. But even with workers and sharding in place, many teams still struggle to maintain efficiency. Test orchestration addresses these challenges.
Test Orchestration: Getting the Best of Both Worlds
Workers and sharding both improve test performance in their own ways, but neither fully solves the problem of distributing work optimally when test durations vary and infrastructure behaves unpredictably. Workers give you dynamic distribution on one machine, sharding gives you horizontal scale with static splits, and the gap between them is where most teams struggle.
Test orchestration fills that gap. Instead of pre-assigning tests to machines and hoping the distribution balances out, orchestration treats test execution as a real-time scheduling problem.

What Orchestration Actually Does
Orchestration replaces static test allocation with a dynamic task queue. When you run tests with orchestration enabled, an external service maintains a list of pending tests. As your CI machines come online, they don't receive a fixed subset of tests upfront. Instead, they pull tasks from the queue in real time, running the test that is next in line.
Here's how it differs from traditional approaches:
With sharding, you split 100 tests across four machines with 25 tests each, but if Shard 4 takes 20 minutes while Shard 1 finishes in 10, your total runtime is 20 minutes with three machines sitting idle for half that time.
With orchestration, all 100 tests go into a queue. Machine 1 might run 30 tests, Machine 2 runs 22 tests, Machine 3 runs 28 tests, Machine 4 runs 20 tests — whatever distribution keeps all machines busy until the queue empties. The orchestrator tracks historical test durations and prioritizes longer tests first, so fast tests fill in gaps at the end instead of creating bottlenecks.
Why This Matters at Scale
Orchestration becomes valuable when you've already combined workers and sharding but still see inefficiency, such as running eight shards with four workers each, where the slowest shard limits your total runtime, and machines finish at wildly different times.
FundGuard encountered this situation when migrating from Cypress to Playwright with an 80-minute end-to-end (E2E) test suite. They implemented Playwright's native sharding, which helped reduce runtime, but they still faced the static split problem where some shards finished quickly while others took significantly longer.
When they enabled Currents Orchestration, their runtime dropped from 80 minutes to 40 minutes, a 50% reduction, by distributing tests based on actual duration data rather than alphabetical file order, ensuring machines that started late didn't hold up the entire run.
Combining Workers, Sharding, and Orchestration
Orchestration doesn't replace workers or sharding; it coordinates them. You configure workers to maximize parallelism on each machine and shard across multiple machines, while orchestration adds intelligence to decide test allocation.
Here’s how they work together: 10 CI machines, each configured with four workers, give you 40 concurrent test slots. Each machine connects to the orchestration service, which maintains a live queue of all tests. As workers on each machine becomes available, they pull the next test from it. Machine 3 might run 45 tests while Machine 7 runs 35, depending on what keeps all 40 slots busy until everything completes.
This three-layer approach maximizes efficiency. Workers handle parallelism within each machine. Sharding distributes load across multiple machines. Orchestration ensures the distribution adapts dynamically so that slow-provisioning machines don't create bottlenecks.
The Cost Optimization Angle
FundGuard took orchestration further by combining it with cloud spot instances, Virtual Machines (VMs) that cost 70–90% less than on-demand instances but can be terminated at any time. Spot instances are attractive for CI workloads because of the cost savings, but their volatility makes them risky. If a spot instance is terminated mid-run, you lose all progress and have to rerun affected tests.
Currents addressed this by implementing a mechanism that detects when a spot instance is about to terminate and automatically moves in-progress tests to a healthy machine, with the orchestrator tracking affected tests to ensure no work is lost without manual intervention.
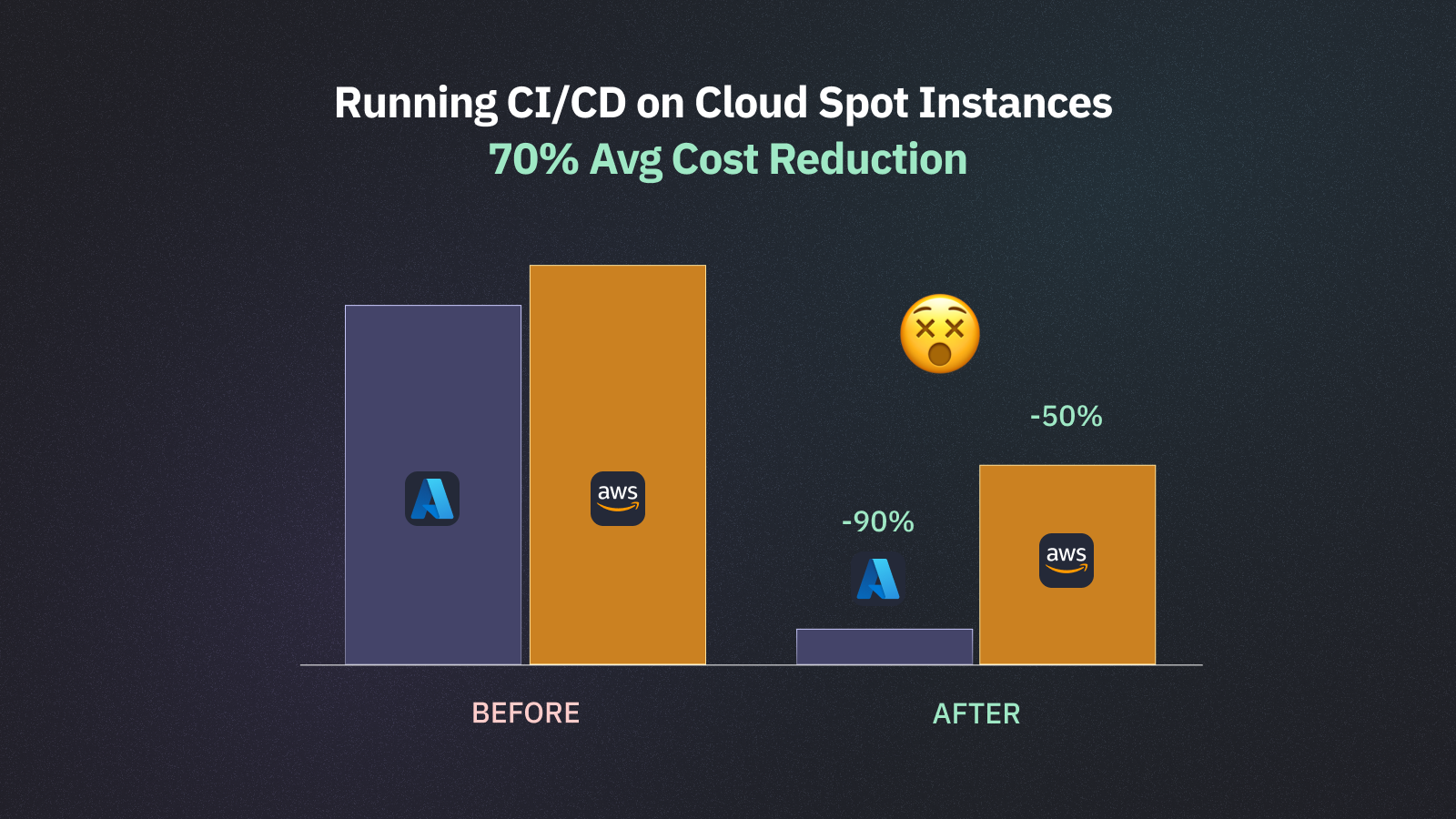
This combination of orchestration and spot instances reduced FundGuard's CI costs by 50% on AWS and 90% on Azure while delivering faster runtimes without sacrificing test stability.
When Orchestration Makes Sense
Orchestration adds complexity by requiring integration of an external service into your CI pipeline, configuring machines to communicate with it, and managing it as another dependency. For teams with small test suites or where static sharding works fine, this complexity isn't justified.
Orchestration fits when you're running sharded tests and facing these problems:
- Runtime variability occurs when shards are unevenly balanced, with some finishing in 15 minutes and others taking 25 minutes unpredictably.
- Infrastructure delays cause specific shards to start late, holding up the entire pipeline and leaving machines idle while slow shards catch up.
- Test suites with 20+ files of varying duration become unsustainable when manual load balancing is required, such as renaming files or reorganizing tests, as the suite grows.
At that point, orchestration stops being an optimization and becomes necessary infrastructure. It turns multiple machines and workers from a coordination problem into a cohesive execution strategy.
Wrap Up
Workers fit teams running hundreds of tests within single-machine limits. Sharding scales horizontally when you've exhausted that capacity. Orchestration optimizes distribution when static splits create imbalances. Start with the approach that matches your current bottleneck, not where you think your suite might grow.
Track results through test analytics, as optimization isn't a one-time task. Runtime degrades as suites evolve, so monitor metrics continuously. Adjust when data shows your approach no longer delivers, using tools like Currents to validate whether your chosen path meets expectations.
Pick the option that solves your bottleneck, implement it, measure it, and iterate from there.
Join hundreds of teams using Currents.
Trademarks and logos mentioned in this text belong to their respective owners.


