The Playwright Network Mocking Playbook
Playwright mocking is easy to start but hard to scale. Follow this practical guide to learn when to mock, when it becomes risky, and how to reduce mock debt.

Network mocking in Playwright is deceptively easy to get started with and deceptively hard to maintain. The mechanics, page.route(), route.fulfill(), routeFromHAR(), are well-documented and quick to pick up. We've seen most teams get a working mock strategy within the first few weeks of adopting Playwright. The problem is that a strategy that passes tests today can become a liability over time, and that gap tends to stay invisible until something breaks in production.
The pattern usually goes like this: A team mocks external API calls to speed up CI, the suite runs fast and reliably, and confidence builds. Then, the real APIs start changing. A payment provider adds a required field. An auth provider changes how token errors are returned. An idempotency policy gets enforced that wasn't before. The mocks don't follow any of this; they stay frozen at the moment they were written, returning responses that once reflected reality but no longer do. By the time the gap surfaces, usually through a customer-facing incident rather than a test failure, the mock debt has been accumulating for months.
What most teams are missing at that point is a decision framework: one that covers when to mock, which flows need to be tested against real systems, and how to keep the two from drifting apart silently. This guide is written for senior SDETs, QA architects, and engineering leaders making suite-wide decisions rather than writing individual tests.
The Mocking Spectrum (Not Binary)
The first thing to get right is the mental model. Mocking is not a switch you flip; it sits on a spectrum, and every position on it carries a different trade-off between speed and fidelity.
Full mocking gets you speed and determinism. Real integrations get you accuracy. Neither extreme is correct across the board, and the question worth asking is where each category of test belongs on that spectrum.
There are five meaningful positions on this spectrum, each with a different cost.
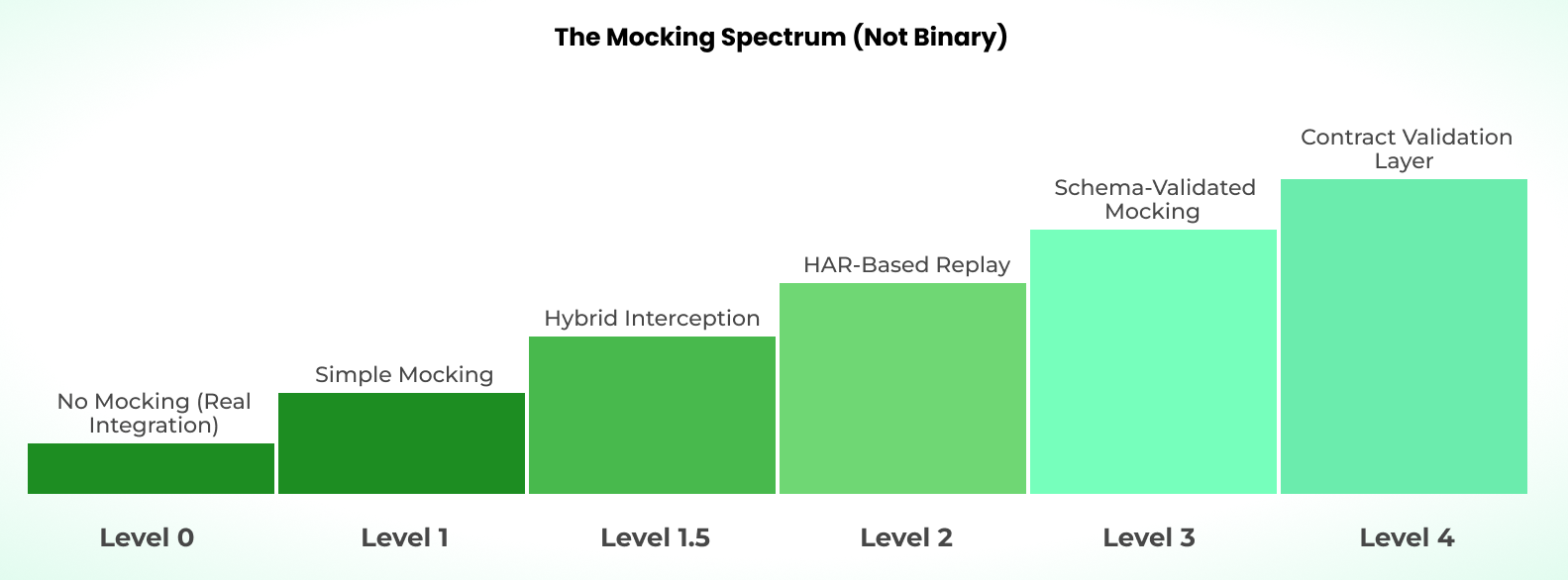
Level 0: No Mocking (Real Integration)
At this level, your tests send real requests to external services, no interception or route handling, just the actual network call hitting a sandbox or test environment maintained by the provider.
test("completes payment with Stripe test credentials", async ({ page }) => {
await page.goto("/checkout");
await page.getByTestId("card-number").fill("4242424242424242");
await page.getByTestId("card-expiry").fill("12/26");
await page.getByTestId("card-cvc").fill("123");
await page.getByTestId("submit-payment").click();
await expect(page.getByText("Payment confirmed")).toBeVisible();
});
Nothing is intercepted here. Stripe's test API receives the request, processes it against real validation logic, and returns a real response.
This example fills card fields directly on the page, which works for simplified checkout implementations. In many production Stripe integrations, sensitive card fields are hosted in Stripe-managed iframes or tokenized via Stripe.js before the form submits, meaning the actual test shape involves backend-mediated payment intent creation followed by webhook confirmation, rather than direct field interaction. The principle is the same; the test mechanics will differ based on how the integration is built.
The fidelity is as high as it gets. You catch real contract issues, credential misconfiguration, redirect behavior, and edge cases in provider logic that a mock will never reproduce. But there are tradeoffs, too. Network latency, dependency on external service uptime, rate limits, and the requirement of sandbox account management. These tests cannot run offline, and they're slower than anything you'll write with mocks.
Use this level for critical payment flows, authentication sequences, and any third-party integration where a silent failure in production carries business or security consequences. These belong in a dedicated integration suite, not your main CI gate.
Level 1: Simple Mocking
Here you intercept requests using page.route() and fulfill them with a static response. The real API is never called.
test("shows order confirmation after successful payment", async ({ page }) => {
await page.route("*/**/api/payments", async (route) => {
await route.fulfill({
json: {
id: "pay_test_123",
status: "succeeded",
amount: 4999,
currency: "usd",
},
});
});
await page.goto("/checkout");
await page.getByTestId("submit-payment").click();
await expect(page.getByText("Order confirmed")).toBeVisible();
});
This test runs in milliseconds. It has no external dependencies, works offline, and is completely deterministic. But it also has no idea whether the real API still returns status: 'succeeded', returns payment_status, or whether amount is now amount_received. This kind of divergence is the beginning of the mock debt.
Use simple mocking for feature-level tests that validate UI behavior or business logic, not for verifying third-party correctness. If the goal of the test is "does the order confirmation screen render correctly when a payment succeeds," a static mock is appropriate. If the goal is "does the payment integration actually work," it is not.
Level 1.5: Hybrid Interception
This pattern sits between simple mocking and full real integration. You call the real API using route.fetch(), then modify only the specific fields you need to control, and return the rest of the real response intact.
test("handles card decline gracefully", async ({ page }) => {
await page.route("*/**/api/payments", async (route) => {
const response = await route.fetch();
const body = await response.json();
// Overlay only the fields needed to simulate the decline scenario.
// Note: passing `response` preserves the original HTTP status code (likely 200).
// If the application branches on HTTP status, override it explicitly with `status: 402`.
await route.fulfill({
response,
status: 402,
json: {
...body,
status: "failed",
error_code: "card_declined",
error_message: "Your card was declined.",
},
});
});
await page.goto("/checkout");
await page.getByTestId("submit-payment").click();
await expect(page.getByText("Your card was declined")).toBeVisible();
});
You're not rewriting the full response shape. You fetch the real response, preserve everything about it, and overlay only the fields that change your test scenario. The structure automatically stays in sync with reality.
It's a good way to simulate hard-to-trigger edge cases (declined cards, expired tokens, rate limit responses) without manually maintaining a full mock that can diverge. The test still has latency and an external dependency because it involves a real network call, so it's not fully deterministic, which slightly understates the risk. If the real API is unavailable, rate-limited, or returns an unexpected shape due to a provider-side change, the test will fail for reasons entirely unrelated to the code under test. That makes Level 1.5 unsuitable for anything running in a gated CI pipeline where false failures are costly. The drift risk, though, drops significantly compared to Level 1.
One thing to know: route.fetch() sends the request directly to the network, bypassing other registered route handlers. This is similar to how route.continue() works. Your other page.route() or context.route() handlers won't intercept the request issued by route.fetch(). If the real API is behind authentication or requires specific headers, pass them as options to route.fetch() directly rather than relying on another handler to add them.
Level 2: HAR-Based Replay
HAR (HTTP Archive) files record real network traffic and let you replay it deterministically. You capture a real session once using routeFromHAR() with update: true, commit the HAR file, and then replay it in subsequent test runs without hitting the live API.
// Record mode: update: true fetches real responses and writes the HAR file
await page.routeFromHAR("./hars/payment-flow.har", {
url: "*/**/api/payments/**",
update: true,
});
// Replay mode: update: false (or omit) serves responses from the HAR file
await page.routeFromHAR("./hars/payment-flow.har", {
url: "*/**/api/payments/**",
update: false,
});
HAR replay provides realistic response payloads, including complex nested structures and headers, without requiring a live dependency. It's particularly useful for integrations with expensive or rate-limited APIs, or for complex filter and search flows where a single static mock can't represent the variety of real responses.
The limitation is that HAR files are static snapshots of real APIs, so they don’t evolve. Unlike Level 1.5, you're not getting the real response on each run, which means drift still accumulates over time. How quickly depends on how often the API changes and how frequently the HAR is refreshed. For a stable API with infrequent breaking changes and regular HAR updates, drift stays manageable. For a fast-moving API with infrequent HAR refresh, drift can accumulate at roughly the same rate as a static mock. HAR files need periodic refresh as APIs change, and that refresh process needs to be deliberate and owned.
Matching behavior: HAR replay matches on URL and HTTP method. For POST requests, Playwright also matches on the request body, which means a POST with a different payload won't match an existing HAR entry and will be treated as unmatched. When multiple entries could match a request, Playwright picks the one with the most matching headers. This can produce surprising behavior in suites where the same endpoint is called with different header combinations across tests.
notFound option: When a request doesn't match any HAR entry, the default behavior is notFound: 'abort', which cancels the request and returns a network error. Setting notFound: 'fallback' passes unmatched requests to the next route handler in the chain. If no other handlers are registered, the request reaches the real network. The fallback mode is useful during HAR development but risky in CI, since it can silently re-introduce real network calls into what appears to be an offline suite. Audit CI logs for unmatched requests when switching between modes.
updateMode and updateContent options: The boolean update: true/false is shorthand. For more control, two options are available. updateMode accepts 'full' or 'minimal' (the default). In minimal mode, Playwright only records information necessary for replay, omitting sizes, timing, page, cookies, security, and other metadata. Use 'full' when you need a complete HAR for debugging or auditing. updateContent accepts 'embed' or 'attach'. With 'embed', response bodies are stored inline in the HAR file. With 'attach', they're persisted as separate files or entries in a ZIP archive. For large HAR files with big response bodies, 'attach' keeps the HAR readable and diffs cleaner in version control.
Write timing: When update: true, Playwright writes the HAR file when the browser context closes, not when the test finishes or when the route handler runs. If a test crashes or the context is closed unexpectedly before the normal teardown, the HAR may be written in a partial or inconsistent state. Always verify HAR files after a record pass before committing them.
Security: HAR files recorded against real or sandbox APIs frequently capture authentication headers, session tokens, and full response bodies. Committing them to source control, which is the natural workflow here, exposes those credentials to anyone with repository access. Scrub auth headers before committing, use environment-specific HAR files excluded from the main branch, or store them in a secrets-aware artifact store rather than the repo itself.
Level 3: Schema-Validated Mocking
At this level, you're still using static mocks, but every mock response is validated against a defined schema before it's returned. If the mock violates the schema, the test fails immediately in CI rather than silently diverging.
import Ajv from "ajv";
const ajv = new Ajv();
const paymentResponseSchema = {
type: "object",
required: ["id", "status", "amount", "currency"],
properties: {
id: { type: "string", pattern: "^pay_" },
status: { type: "string", enum: ["succeeded", "failed", "pending"] },
amount: { type: "integer", minimum: 0 },
currency: { type: "string", minLength: 3, maxLength: 3 },
},
additionalProperties: false,
};
const validate = ajv.compile(paymentResponseSchema);
test("confirms order on successful payment", async ({ page }) => {
await page.route("*/**/api/payments", async (route) => {
const mockResponse = {
id: "pay_test_123",
status: "succeeded",
amount: 4999,
currency: "usd",
};
// Fail fast in CI if mock violates the contract
if (!validate(mockResponse)) {
throw new Error(
`Mock violates schema: ${JSON.stringify(validate.errors)}`,
);
}
await route.fulfill({
status: 200,
contentType: "application/json",
body: JSON.stringify(mockResponse),
});
});
await page.goto("/checkout");
await page.getByTestId("submit-payment").click();
await expect(page.getByText("Order confirmed")).toBeVisible();
});
When Stripe adds a required field to their response, and you update your schema, any mock that doesn't include that field breaks immediately. You've shifted the failure from production to CI, which is exactly where you want it.
What schema validation gives you is internal consistency: an assurance that your mocks conform to the expectations you've defined. Whether the real API still behaves the way those expectations describe is a separate question, and one that schema validation alone can't answer.
ajv provides runtime validation, which catches schema violations when tests execute. For teams that want to catch mock drift earlier, at compile time rather than in CI, openapi-typescript can generate TypeScript types directly from an OpenAPI spec. openapi-fetch provides a type-safe client built on those types. If you type your mock builders explicitly against those generated response types, TypeScript will flag structural mismatches in your editor before the test runs. This doesn't happen automatically with untyped mock objects; the benefit only applies when the mock is declared with the generated type annotation.
The tradeoff is setup complexity and a harder dependency on provider spec quality. For mature, well-maintained APIs like Stripe, Auth0, or Twilio, the compile-time approach is worth the investment. For less reliable specs, runtime validation with ajv is more practical.
Use this level for high-risk integrations where real API tests are too slow for daily execution, and where structural drift in your mocks would be costly.
Level 4: Contract Validation Layer
At this level, a small integration suite runs against the real external API using test credentials to verify that the live provider behaves as your mocks expect. The idea is pretty simple: If the contract test passes, your mocks are grounded in reality. If it fails, you know immediately that the real API has changed and your mocks need to catch up, before that gap reaches production.
// Contract test: runs in integration suite against the real API
test("validate live Stripe payment response matches contract", async ({
request,
}) => {
const response = await request.post(
"https://api.stripe.com/v1/payment_intents",
{
headers: { Authorization: `Bearer ${process.env.STRIPE_TEST_KEY}` },
form: {
amount: "999",
currency: "usd",
payment_method: "pm_card_visa",
confirm: "true",
},
},
);
const body = await response.json();
// Validate real response against the shared contract schema
const valid = validate(body);
expect(
valid,
`Live API violates contract: ${JSON.stringify(validate.errors)}`,
).toBe(true);
});
Note that pm_card_visa is a Stripe test-mode token that bypasses 3D Secure and other authentication challenges. Real payment methods that require SCA will return requires_action instead of completing immediately. Contract tests using test tokens validate the response shape, not the full authentication flow. If your integration handles requires_action states, add a separate contract test using a token like pm_card_authenticationRequired to cover that path.
If Stripe changes the shape of their response, this contract test fails first. That failure blocks CI and forces your team to update mocks intentionally rather than discovering drift weeks later in production.
The tradeoff is complexity and speed. These tests need external connectivity and take longer to run. They belong in a scheduled integration pipeline, not the main CI gate for every commit. Use this level for payments, authentication, identity, and any integration where contract drift would cause customer impact.
The spectrum is a planning tool. Levels 3 and 4 are where it gets interesting because they add validation layers that recover accuracy without giving up the speed of mocked tests. Apply each level based on what the test is actually trying to verify.
If you can only invest in one validation layer, start with schema validation (Level 3). It's cheaper to adopt than contract testing and catches the most common category of drift: structural changes. HAR replay (Level 2) gives you realistic payloads but no structural guarantees; if you're choosing between HAR and schema validation with limited time, schema validation protects you more. Add contract tests (Level 4) once your highest-risk integrations have schemas in place and you need to close the behavioral drift gap.
Route Handler Mechanics
Before scaling a mock strategy across a large suite, you need to understand how Playwright's route handlers interact. These mechanics apply to every mocking level.
page.route() vs. context.route(): page.route() applies only to the page it's registered on. browserContext.route() applies to all pages opened within that browser context. When both a page route and a context route match the same request, the page route takes precedence. Shared fixtures often use context.route() to set up global interception across all pages in a test, while individual tests use page.route() for narrower overrides, relying on page routes winning when both match.
Handler registration order: When multiple handlers of the same scope match the same URL pattern, Playwright runs them in reverse registration order; the last handler registered executes first. What determines which handler fires first is purely when it was registered, not whether it came from a fixture or a test. If a fixture registers a handler at setup time and the test registers a second handler for the same pattern afterward, the test's handler fires first. If the order is reversed (fixture registers after the test), the fixture's handler fires first. Suites that mix fixture-level and test-level handlers for the same patterns need to be deliberate about registration sequence.
route.continue() vs. route.fallback(): When working with multiple handlers on the same route, the method used to pass control matters. route.continue() sends the request to the network and stops handler chaining; no further handlers run for that request. route.fallback() passes the request to the next matching handler in the chain (the one registered before it) without sending it to the network yet.
The common fixture pattern works like this: the fixture registers a handler first (so it sits last in the chain), and the test registers its handler second (so it fires first). When the test handler wants to override the response, it calls route.fulfill() directly. When it doesn't need to override, it calls route.fallback() to let the fixture handler take over. The fixture handler then calls route.fulfill() or route.continue() as the final handler in the chain. Use continue() when a handler should be the final word and should send the request to the network.
Service workers: If the page under test uses a service worker that intercepts network requests, that worker may handle requests before Playwright's route handlers see them. This is a known limitation of browser-level request interception. If your test target registers a service worker, disable it by setting serviceWorkers: 'block' in your browser context options (or in playwright.config.ts under use), or use context.addInitScript to prevent service worker registration. Either approach ensures Playwright's route handlers see all requests.
Cleanup: In complex fixture setups, route handlers can leak between tests if not cleaned up properly. page.unroute(url) removes all handlers registered for that URL pattern. To remove a single specific handler, pass it as the second argument: page.unroute(url, handler). For removing everything at once, both page.unrouteAll() and browserContext.unrouteAll() are available (since v1.41). These also remove handlers registered via routeFromHAR().
unrouteAll() accepts a behavior option that controls how in-flight handlers are treated: 'wait' waits for running handlers to finish, 'ignoreErrors' silently catches errors thrown by handlers after unrouting, and 'default' does neither (which can cause unhandled errors if a handler throws after being removed). In fixture teardown, 'wait' is the safest choice. Leaked handlers are a common source of flaky behavior in large suites because a handler from a previous test silently intercepts requests in the next one.
Mock Debt and Smart Mocking Guardrails
Mock debt accumulates silently until something breaks in production that your test suite never expected.
Here's what that looks like in practice, using a payment integration as the example:
-
Month 0: You mock your payment endpoint. The real Stripe API returns
{ status: 'succeeded' }on success, and your mock returns the same, indicating the debt is zero. -
Month 1: Stripe adds a new field to their response:
charge_id. The real API now returns{ status: 'succeeded', charge_id: 'ch_abc123' }, but your mock still returns only{ status: 'succeeded' }. Tests pass without anyone noticing. -
Month 2: A new feature on your checkout page reads
charge_idto display the transaction reference. In production, the field is there, but in tests it's not, so the feature test passes without ever exercising that path. -
Month 3: Stripe changes how declined card errors are returned. Previously, they returned a generic error, and now they return
{ status: 'failed', error_code: 'card_declined', decline_code: 'insufficient_funds' }. The error-handling code branches onerror_code; the mock doesn't have that field, tests pass, and production incorrectly handles declined cards. -
Month 4 (behavioral drift): Stripe tightens validation on payment method types. The response shape is identical, but requests that previously succeeded with a generic
payment_method: 'card'now requirepayment_method_types: ['card']. Your mock doesn't validate request payloads, so the test keeps passing. In production, payment creation starts failing intermittently for certain flows. No schema validator catches this because the response structure hasn't changed. Only the API's input validation rules have. -
Beyond 4 months: Stripe's newer API version requires idempotency keys on payment creation requests and now rejects requests without them. The mock accepts anything, so tests pass while production starts rejecting valid payment attempts intermittently under load.
At this point, tests are green while customer payments are failing, and the engineering team spends two weeks tracing an incident whose root cause is a nine-month-old mock that nobody touched.
This is a common failure pattern: A payment provider adds a required idempotency-key enforcement policy, mocks don't validate it, production starts rejecting requests, and the failure surface is wide enough that it takes days to isolate. The mocks were stale, the tests were passing, and the real contract had changed months ago.
The trap is that mock debt is invisible until it becomes expensive. And by the time it's visible, you're usually looking at a production incident. Mocks drifting from real API behavior is also one of the less obvious sources of test flakiness; tests that pass in isolation but behave unpredictably across environments often have a stale mock somewhere in the chain. The guide on flaky tests covers how to diagnose and address those patterns more broadly.
Structural Drift vs. Behavioral Drift
Two categories of drift require different responses, and the distinction matters because each needs a different guardrail.
Structural drift is when the contract shape changes, on either side of the request. Response fields get added or removed, types change, formats evolve. On the request side, a previously optional parameter becomes required, a field gets renamed, or an enum gains new allowed values. Response-side structural drift is detectable through schema validation. Request-side structural drift is harder to catch because mocks don't validate what your code sends, only what the mock returns. If your mock returns amount as a string and the real API now returns it as an integer, a schema validator will catch it. If the real API now requires a currency parameter your code never sends, nothing in the mock layer will tell you.
Behavioral drift is harder to detect because the response shape remains the same while the underlying logic changes. Retry behavior evolves, validation rules tighten, error codes get remapped, and token expiration windows shrink. A mock can return all the right fields in all the right formats and still be wrong in ways no schema will ever catch because the schema only describes structure. Surfacing behavioral drift requires real integration tests, because static mock validation has no way of telling you whether the real payment processor now enforces idempotency keys or whether an auth provider has changed how it handles expired sessions.
Both categories exist at once. Your guardrail strategy needs to address both.
Guardrail 1: JSON Schema Validation
Every critical mock should be validated against a schema that represents the expected API contract. This is the same approach described in Level 3 of the spectrum, applied systematically across the suite.
Define the schema explicitly using a tool like ajv, then validate every mock response against it before fulfilling the route. When the real API adds a required field and the schema gets updated to reflect that, any mock in the suite that hasn't been updated breaks immediately in CI. For example, when charge_id gets added to a Stripe response, adding it to your shared schema immediately flags every mock that's missing it. The failure shows up in CI, not in a production incident review.
Schema validation catches missing fields, wrong types, invalid enums, and format violations. What it can't do is verify whether the real API's logic still matches what the mock assumes.
Guardrail 2: Contract Testing Against the Real API
Schema validation catches structural problems. Contract testing confirms that the actual system still behaves as expected by your schema. This is conceptually similar to consumer-driven contract testing tools like Pact, but focused on third-party APIs where you're the only consumer and have no influence over the provider's release process.
The idea is to maintain a small integration suite that runs against real external APIs using test credentials. When the real API changes, the contract test fails first, signaling the team to update mocks intentionally rather than discovering the drift months later through a production incident.
Keep this suite lean. A small number of tests covering critical paths and response shapes is enough, since the goal is early warning rather than exhaustive coverage. Running contract tests on every commit is usually impractical given latency and rate limits, so a nightly schedule or a run tied to release branches is usually the right cadence for most teams.
Guardrail 3: OpenAPI or Published Spec Validation
When a provider publishes an OpenAPI or Swagger specification, use it as a primary reference for your mock responses rather than maintaining a schema from scratch. Validate your mock responses directly against the provider's official spec instead of a schema you maintain manually.
This removes guesswork about required fields and keeps your mocks aligned with the documented contract. When the provider updates their spec, your validation breaks, and that break is an actionable signal.
This is particularly effective for mature, versioned, well-maintained APIs, such as payment providers, storage services, and identity platforms.
For any integration where failure would affect revenue or customer trust: adopt the official spec, validate mock responses against it, and add contract tests that hit the real API in an integration suite. Keep feature tests fast by mocking against that validated contract.
What Should You Mock? The Decision Matrix
Drive mocking decisions by risk, cost, and how often the external API changes, not by convenience.
For each external request in your suite, work through these questions:
-
How critical is this to the product? If failure in this flow affects revenue, security, or core user journeys, include real integration tests. If it supports secondary functionality, mocking is usually appropriate.
-
What is the cost of getting it wrong? If a mistake here causes revenue loss, security exposure, or direct customer harm, validate against the real service. If the impact is limited and recoverable, mocking with schema validation is acceptable.
-
Who controls the API? If you own it, you have visibility into changes and can choose between real testing and contract verification. If it's a third-party service, drift risk is higher because you have no visibility into upcoming changes. Some real verification is required.
-
Does a formal contract exist? If the provider publishes a versioned spec, you can mock it using schema validation. If no explicit contract exists, rely more heavily on real integration tests.
-
What is the operational cost of real testing? If real calls are free or sandboxed with no meaningful rate limits, prefer testing with real calls. If real calls incur cost or consume quota, mock most tests and validate with a small integration suite.
Decision Patterns by Category
Critical third-party systems (payments, authentication)
A layered approach works best here; a small integration suite hits the real API with test credentials to validate the contract, while feature tests mock against that verified contract to preserve speed. The two suites serve different purposes and run at different cadences, but they stay in sync because the integration tests are the source of truth for what the mocks should reflect.
// Integration test: validates the real contract
test("validate Stripe payment intent creation", async ({ request }) => {
const response = await request.post(
"https://api.stripe.com/v1/payment_intents",
{
headers: { Authorization: `Bearer ${process.env.STRIPE_TEST_KEY}` },
form: { amount: "999", currency: "usd" },
},
);
expect(response.ok()).toBeTruthy();
const body = await response.json();
expect(body).toHaveProperty("id");
expect(body.status).toBe("requires_payment_method");
});
// Feature test: validates UI behavior against a verified mock
test("shows payment form after initialization", async ({ page }) => {
await page.route("*/**/api/payment-intent", async (route) => {
await route.fulfill({
status: 200,
contentType: "application/json",
body: JSON.stringify({
id: "pi_test_123",
client_secret: "pi_test_123_secret_abc",
status: "requires_payment_method",
}),
});
});
await page.goto("/checkout");
await expect(page.locator('[data-testid="payment-form"]')).toBeVisible();
});
Internal APIs
Prefer real calls in integration tests because you control the code and have full visibility into changes. Mock in UI-level tests where speed or isolation is needed.
// Integration test: hit the real internal endpoint
test("user profile loads correctly", async ({ request }) => {
const response = await request.get("/api/users/me", {
headers: { Authorization: `Bearer ${process.env.TEST_USER_TOKEN}` },
});
expect(response.ok()).toBeTruthy();
const user = await response.json();
expect(user).toHaveProperty("id");
expect(user).toHaveProperty("email");
});
Stable third-party APIs with published contracts
Mock with schema validation. Add periodic contract validation tests to detect drift. The published spec is your contract; treat any deviation from it as a test failure.
Expensive or rate-limited services (SMS, email providers)
Mock for most tests. Add minimal real validation in a scheduled integration pipeline. A weekly run against a test account is enough to catch contract drift without consuming quota.
Logging and analytics systems
Mock completely. Verify that the correct payload is generated rather than sending real events. The goal is to assert on what you're sending, not to validate the analytics provider's backend.
test("tracks purchase event on checkout completion", async ({ page }) => {
const analyticsRequests: unknown[] = [];
await page.route("*/**/analytics/track", async (route) => {
const body = route.request().postDataJSON();
analyticsRequests.push(body);
await route.fulfill({ status: 200, body: "{}" });
});
await page.goto("/checkout");
await page.getByTestId("complete-purchase").click();
const purchaseEvent = analyticsRequests.find(
(r: any) => r.event === "purchase_completed",
);
expect(purchaseEvent).toBeDefined();
expect((purchaseEvent as any).properties.amount).toBe(4999);
});
When Not to Mock: The Must-Test-Real List
Some flows carry enough risk that simulated behavior isn't a sufficient substitute for the real thing. When failure in production would have a material business impact, such as revenue loss, locked-out users, or a compliance violation, those paths need to be exercised against real systems, at minimum in a dedicated integration suite that runs alongside the main test gate.
Payment Processing
Payment systems are among the most complex third-party integrations a product team deals with. They handle currency conversion, fraud signals, idempotency enforcement, retry behavior, and webhook lifecycles, and each of those dimensions has edge cases that a static mock will never exercise.
A mock can confirm that the UI renders "Payment successful" after a fulfilled request, but it won't catch a misconfigured API key, an invalid token format, a webhook signature mismatch, or a subtle contract change that the payment provider shipped in a recent API version. Running real payment tests against official sandbox environments like Stripe's test mode validates the full lifecycle and keeps those gaps visible. Feature tests should still mock for speed, but a dedicated integration suite running in parallel is what gives those mocks meaning.
Authentication Flows
OAuth, SSO, and MFA flows are particularly vulnerable to mock drift because they involve redirect chains, token exchanges, expiration handling, refresh logic, and provider-side security enforcement, all of which interact in ways that are difficult to simulate accurately.
Mocking login responses tends to hide redirect bugs, token validation errors, and session management changes that the provider has made without announcing them loudly. Mocking authentication in feature tests is still reasonable for speed, but a real authentication suite using test credentials should always exist alongside it to validate the full flow end-to-end.
For feature tests that require an authenticated state but aren't testing the auth flow itself, Playwright's storageState is the right tool. Run the login flow once in a setup project, save the resulting cookies and localStorage to a file, and load that state into each test that needs it. This avoids running the full login sequence on every test without mocking any auth responses.
// tests/auth.setup.ts — runs once before the test suite
import { test as setup } from "@playwright/test";
const authFile = "playwright/.auth/user.json";
setup("authenticate", async ({ page }) => {
await page.goto("/login");
await page.getByTestId("email").fill(process.env.TEST_USER_EMAIL!);
await page.getByTestId("password").fill(process.env.TEST_USER_PASSWORD!);
await page.getByTestId("submit").click();
await page.waitForURL("/dashboard");
await page.context().storageState({ path: authFile });
});
// playwright.config.ts — setup project runs first, tests reuse its state
export default defineConfig({
projects: [
{ name: "setup", testMatch: /.*\.setup\.ts/ },
{
name: "authenticated",
use: { storageState: "playwright/.auth/user.json" },
dependencies: ["setup"],
},
],
});
The real auth suite validates the login flow against the actual provider. storageState avoids repeating that flow in every feature test while keeping the authentication itself real.
Security-Critical Logic
Permission enforcement, password validation, rate limiting, and CSRF protections are areas where mocked outcomes can produce a false sense of security. A mock that unconditionally returns "authorized" tells the test nothing about whether the actual access control layer is working correctly.
Security logic needs to be exercised against real enforcement layers. A gap here means a potential breach.
That said, this guidance is often applied too broadly. Mocking is the right approach when the goal is to verify how your application responds to an authorization failure, like testing that a 403 response correctly redirects to an error page or that a rate-limit 429 triggers a retry with backoff. Those are application behavior tests, and a mock gives you reliable control over the scenario.
Real enforcement testing is needed when the goal is to verify that the enforcement layer itself works correctly. This means confirming that a user without the right role actually receives a 403, that a rate limit fires at the correct threshold, and that a CSRF token check rejects forged requests. These tests need to exercise the real enforcement mechanism, not a simulation of its output.
For UI tests that simply require an authenticated state to reach the feature being tested, not to validate the authentication or authorization logic itself, neither mocking auth responses nor running a live login flow is necessary. Use storageState to load a pre-authenticated session, as described in the authentication flows section above, and keep those tests focused on the UI behavior they're actually verifying.
The question to ask for each security-adjacent test is: Am I testing my application's response to a security event, am I testing that the security event fires correctly, or am I simply testing a feature that happens to require an authenticated user? Each of those is a different answer.
High-Impact Error Handling
When a system depends on correctly handling specific error codes, retry sequences, or provider validation responses, happy-path mocks leave the error-handling paths untested in any meaningful way.
Mocking error scenarios deliberately and exhaustively, with schema validation on the mock responses, covers some of this ground. For the highest-stakes paths, real integration tests against sandbox error conditions are the only way to know for certain that the handling works as intended.
Compliance-Sensitive Flows
Data deletion requests, audit log generation, and access control monitoring are areas where regulatory evidence depends on real system behavior, not test output. If an auditor asks for proof that a deletion request was handled correctly, a passing test assertion against a mocked response carries no weight. These flows need to run against real infrastructure to produce evidence that means something.
Webhooks and Asynchronous Integrations
Most mocking strategies focus entirely on request-response flows, which cover only part of how modern integrations actually work.
Payments, identity, and subscription systems are fundamentally asynchronous. Stripe, for example, in addition to responding to a charge request, also sends webhooks for payment intent updates, dispute creation, refunds, and subscription lifecycle events. When a test mocks the outbound API call but never exercises the inbound webhook flow, it's validating half the interaction and treating it as the whole thing.
Webhooks change the interaction model in ways that are easy to underestimate. State transitions happen asynchronously, driven by events the application receives and must process correctly. The webhook endpoint needs to handle delivery retries when it's temporarily unavailable. It needs to validate signatures to confirm the payload originated with the provider. It needs to handle out-of-order delivery gracefully, which means handlers need to be idempotent. None of that complexity shows up in a page.route() mock on the outbound request.
Testing webhook flows properly requires a different set of approaches:
- Post test payloads directly to your webhook handler endpoint in integration tests
- Replay real webhook payloads captured from provider sandbox events
- Validate the payload shape against the provider's documented event schema
- Run a dedicated integration suite that covers the full asynchronous lifecycle
Here's what a basic webhook integration test looks like using Playwright's request fixture to POST a test payload directly to your webhook handler:
test("processes Stripe payment_intent.succeeded webhook", async ({
request,
}) => {
const webhookPayload = {
id: "evt_test_123",
type: "payment_intent.succeeded",
data: {
object: {
id: "pi_test_456",
amount: 4999,
currency: "usd",
status: "succeeded",
},
},
};
const response = await request.post("/api/webhooks/stripe", {
data: webhookPayload,
headers: {
"Content-Type": "application/json",
"Stripe-Signature": generateTestSignature(webhookPayload),
},
});
expect(response.ok()).toBeTruthy();
// Verify the webhook handler updated the order status
const order = await request.get("/api/orders/pi_test_456");
const orderData = await order.json();
expect(orderData.status).toBe("paid");
});
Stripe computes signatures using HMAC-SHA256 with a timestamp and the raw payload body. In test environments, use the webhook signing secret from your Stripe dashboard's test mode to generate valid signatures:
import crypto from "crypto";
function generateTestSignature(
payload: object,
secret: string = process.env.STRIPE_WEBHOOK_SECRET!,
): string {
const timestamp = Math.floor(Date.now() / 1000);
const payloadString = JSON.stringify(payload);
const signedPayload = `${timestamp}.${payloadString}`;
const signature = crypto
.createHmac("sha256", secret)
.update(signedPayload)
.digest("hex");
return `t=${timestamp},v1=${signature}`;
}
This lets you exercise the handler's signature validation, payload parsing, idempotency checks, and the resulting state change. One caveat: this test signs the payload using JSON.stringify(), which may differ from how Stripe serializes the raw body in real webhook deliveries (key ordering, whitespace). The test confirms your handler can verify a correctly-signed payload, but it doesn't guarantee compatibility with Stripe's exact serialization. For full confidence, capture a real webhook payload from Stripe's test mode dashboard and use the raw body bytes for signing.
Bypassing signature verification in tests is tempting but defeats the purpose. If your handler has a bug in signature checking, you want to catch it here.
For idempotency, send the same webhook event twice and verify the handler doesn't create duplicate records:
test("webhook handler is idempotent", async ({ request }) => {
const webhookPayload = {
id: "evt_test_idempotent",
type: "payment_intent.succeeded",
data: {
object: {
id: "pi_test_789",
amount: 2000,
currency: "usd",
status: "succeeded",
},
},
};
const signature = generateTestSignature(webhookPayload);
const headers = {
"Content-Type": "application/json",
"Stripe-Signature": signature,
};
await request.post("/api/webhooks/stripe", { data: webhookPayload, headers });
await request.post("/api/webhooks/stripe", { data: webhookPayload, headers });
const orders = await request.get("/api/orders?payment_intent=pi_test_789");
const ordersData = await orders.json();
expect(ordersData.length).toBe(1);
});
The right mix depends on the integration. But if a feature depends on a webhook and your tests never exercise that delivery path, you're leaving the most failure-prone part of the flow untested.
WebSocket Mocking
If your application uses WebSocket connections for real-time features (live dashboards, chat, collaborative editing), Playwright supports WebSocket interception natively via page.routeWebSocket(). You can mock the entire WebSocket communication without connecting to the server, or connect to the real server and intercept messages in transit to modify or block specific ones.
await page.routeWebSocket("wss://example.com/ws", (ws) => {
ws.onMessage((message) => {
if (message === "request") ws.send("response");
});
});
WebSocket mocking follows different patterns than HTTP mocking. There's no request-response cycle to intercept; instead, you're managing a persistent bidirectional channel where either side can send messages at any time. The same drift concerns apply: if the server changes its message format or protocol, a mocked WebSocket won't tell you. For real-time features where message ordering or reconnection behavior matters, include integration tests against the real WebSocket server alongside your mocked tests.
Implementation Roadmap: From Aggressive Mocking to Smart Mocking
Here's an eight-week path from uncontrolled mocks to validated ones.
Phase 1: Audit Your Current Mocks (Weeks 1-2)
Search your test suite for every page.route() and request interception.
A simple grep across the codebase; grep -r "page\.route\|context\.route\|routeFromHAR" --include="*.ts" -l, gives you the file list quickly. For teams wanting more structure, a custom Playwright reporter that hooks into route events and logs intercepted URLs during a dry run can generate the inventory automatically, including request frequency and which tests own each interception. Build a simple inventory with four columns: which endpoint is mocked, how critical it is to revenue or security, when it was last verified against the real API, and whether it has any documentation.
That inventory is your risk map. Coming out of this phase, you should know your total mock count, which mocks are business-critical, which have never been validated, and which have no owner. Everything that follows is prioritized by it.
Phase 2: Add Schema Validation to Critical Mocks (Weeks 3-4)
Don't try to fix everything. Start with the top 10 highest-risk mocks identified in your audit. For each one, define a JSON schema or adopt the provider's published OpenAPI spec, add a validation step in the test that ensures the mock response conforms, and configure it to fail fast if the structure drifts.
After these two weeks, your most important mocks cannot silently diverge in shape. Structural drift becomes immediately visible in CI.
Phase 3: Introduce Contract Tests for Highest Risk Integrations (Weeks 5-8)
Select the three to five mocks where failure would cause customer impact or revenue loss. For each, create a contract test that runs against the real API in your integration suite, validate real responses against the shared schema, and use that contract as the source of truth for feature test mocks.
This creates a feedback loop: real API changes fail contract tests, those failures trigger mock updates, and the updates are validated against the same schema.
Phase 4: Ongoing Maintenance (Week 9 and Beyond)
Mock accuracy is not a one-time fix. Establish a monthly review of critical mocks, subscribe to API changelogs for your highest-risk providers, assign ownership per integration, and configure alerting for contract test failures. Without clear ownership per integration, mock maintenance stalls.
The cultural approach to building reliable Playwright tests goes deeper into how to build that kind of shared ownership across teams.
Playwright's tagging system gives you a practical way to enforce that ownership at the test level. Tag contract tests by integration using test annotations or the @tag syntax in the test title, then use --grep to scope CI runs to a specific integration's tests:
test(
"@payments validate Stripe contract",
{ tag: "@payments" },
async ({ request }) => {
// contract test for payments integration
},
);
test(
"@auth validate Auth0 token endpoint",
{ tag: "@auth" },
async ({ request }) => {
// contract test for auth integration
},
);
Running npx playwright test --grep @payments in a scheduled payments-specific pipeline, and npx playwright test --grep @auth in a separate auth pipeline, means each team owns the CI signal for their integration. test.info().annotations can carry additional metadata, owner, last-verified date, linked spec URL, that shows up in test reports and makes the inventory from Phase 1 self-documenting over time.
In about two months, you go from fragile mocks to a setup where your critical paths are validated and the remaining risk is known rather than invisible.
Test Data Lifecycle When Testing Real Integrations
Moving from mocks to real integration tests introduces operational concerns that will break your suite if you don't address them upfront. Every team that builds a real integration suite hits the same three problems. Here's how to solve each one.
-
Idempotency management is the first one. Payment APIs and many other transactional services reject or mishandle duplicate requests. Your integration tests need unique idempotency keys per run. Using deterministic keys based on test identifiers, like a combination of the test name and a run ID, prevents collisions across parallel runs without requiring random generation.
-
The cleanup strategy matters more than most teams account for. Real integration tests create real objects in sandbox environments, like users, payments, tenants, and orders. Without cleanup, these accumulate and can eventually interfere with each other or hit sandbox limits. Delete created objects when the API supports it. Tag test artifacts consistently with a prefix that includes a unique run identifier so periodic cleanup jobs can find and remove them without touching objects from other runs. A static prefix like
test_is a good start but isn't sufficient when multiple CI pipelines run against the same sandbox simultaneously; a feature branch run and a main branch run will create objects with identical prefixes that a cleanup job can't reliably distinguish. Injectprocess.env.TEST_RUN_IDorprocess.env.GITHUB_RUN_ID(in GitHub Actions) into the prefix to make it unique per run:const runId = process.env.TEST_RUN_ID ?? process.env.GITHUB_RUN_ID ?? "local"; const testPrefix = `test_${runId}_`; // Use when creating sandbox objects const customer = await stripe.customers.create({ email: `${testPrefix}user@example.com`, metadata: { test_run: runId }, }); -
The
metadatafield is particularly useful as it gives cleanup jobs a structured query target (list customers wheremetadata.test_run = <runId>) rather than relying on string prefix matching on names. Don't rely on manual cleanup -
Rate limits and throttling require that integration tests run outside your main CI gate. Tag them separately, apply backoff strategies for retries, and schedule them in a pipeline that doesn't block every commit. A nightly or per-release schedule is appropriate for most teams.
Skip any of these three and your integration suite will work for a few weeks, then slowly degrade until someone disables it. Get all three right from the start and the suite stays reliable without ongoing heroics.
Making Mock Drift Visible
The framework is simple to state and requires discipline to maintain: If the cost of failure is higher than the cost of testing real, test real. Apply it to every external dependency in your suite, and revisit it every time a new integration is added or an existing one changes in scope.
If a mock has ever caused a production incident, it earns contract testing. If mocking strategy is one part of a broader Playwright adoption effort, the guide on adopting Playwright the right way covers how to approach that rollout structurally.
Mock debt is technical debt that hides in plain sight. Tests are green, CI is fast, and somewhere in the suite, a mock hasn't matched reality for months. The guardrails covered here won’t remove the risk entirely. What they do is make it visible and auditable, so the gap shows up in CI before it reaches production.
Join hundreds of teams using Currents.
Trademarks and logos mentioned in this text belong to their respective owners.


